
The question driving hundreds of Google searches since early April (how many parameters does Claude Mythos Preview have) has a simpler answer than the speculation suggests. Anthropic hasn’t said. What Anthropic has said, on the record, is more striking than any parameter count.
Claude Mythos Preview is Anthropic‘s new top-tier model, announced on April 7, 2026, and the first model to sit above Opus in the Anthropic hierarchy. Access runs through Project Glasswing, a closed coalition of roughly 50 critical-infrastructure organizations, not through the Claude API that anyone with a credit card can call. The parameter count is not public. The benchmark scores are, and they are what every serious reader should focus on. Mythos Preview scored 93.9% on SWE-bench Verified against Opus 4.6’s 80.8%. It cleared 97.6% of USAMO 2026 against Opus 4.6’s 42.3%. It scored 83.1% on CyberGym against Opus 4.6’s 66.6%, and it saturated Cybench at 100% pass@1. The official AWS Bedrock model card lists a 1M-token context window, 128K-token output ceiling, December 2025 knowledge cutoff, and a gated research-preview status. The official system card runs 244 pages. Mythos Preview will cost $25 per million input tokens and $125 per million output tokens whenever Anthropic opens the gate. Anthropic has said publicly it does not plan to.
That is what is confirmed. The popular “10 trillion parameters” figure is not.
| Claim | Status | Source |
|---|---|---|
| Parameter count | Not disclosed. “10 trillion” is post-leak speculation, never stated by Anthropic. | Anthropic announcement, Glasswing page, Bedrock model card (all silent). |
| Announcement date | April 7, 2026 | Anthropic red-team paper; AWS Bedrock model card |
| First leaked | March 26, 2026 (CMS misconfiguration) | Fortune |
| Internal codename | “Capybara” reported by secondary coverage, not used in Anthropic’s public pages | Post-leak blog coverage |
| Tier position | Above Opus. Reported lineup: Haiku → Sonnet → Opus → Mythos | Secondary launch coverage |
| Context window | 1M tokens input; 128K tokens output | AWS Bedrock model card |
| Knowledge cutoff | December 2025 | AWS Bedrock model card |
| System card length | 244 pages (with clinical psychiatrist assessment section, a Claude first) | Launch recaps |
| API pricing (post-preview) | $25 / $125 per million input/output tokens | Anthropic Glasswing page |
| Access program | Project Glasswing: 12 launch partners + ~40 critical-infrastructure orgs | Anthropic Glasswing page |
| General availability | “We do not plan to make Claude Mythos Preview generally available.” | Anthropic Glasswing page |
The March 26 CMS leak, and why the parameter-count rumor started there
The search volume around “claude mythos parameter count” and “claude mythos 10 trillion parameters” did not come from the April 7 announcement. It came from the leak twelve days earlier.
On Thursday, March 26, 2026, Anthropic acknowledged that a misconfiguration in its content management system had exposed roughly 3,000 internal assets, including an early draft blog post about the unreleased Mythos model. Fortune broke the story that evening. In its statement, Anthropic called the material “early drafts of content considered for publication” and described the model as “a step change” in AI performance and “the most capable we’ve built to date.” Anthropic also told Fortune the team was “developing a general purpose model with meaningful advances in reasoning, coding, and cybersecurity.”
What the leaked draft did not include (and this is the part that matters for anyone trying to nail the parameter number) was an official parameter count. The Fortune reporting, which is the cleanest first-hand account of what was in the cache, does not list a “10 trillion parameter” figure. Anthropic’s own official statement about the leak does not either. The “10 trillion” number emerged in the days afterward, propagated through Medium posts, Substack explainers, and aggregator blogs that treated the leak as license to speculate about architecture.
This is the honest state of play. Someone, somewhere, wrote “10 trillion” into a blog post. The number got repeated. It got reposted. It started ranking for the exact queries driving traffic today. But if you pull up Anthropic’s April 7 announcement page, the red-team paper signed by Nicholas Carlini, Keane Lucas, and 19 other Anthropic researchers, the 244-page system card, or AWS Bedrock’s official model card, you will not find a parameter count anywhere. Anthropic has not published one. They appear to have decided not to.
Why does that matter? Because the questions that actually determine whether Mythos changes your work have nothing to do with the parameter number and everything to do with what Anthropic has disclosed: the benchmark scores, the vulnerability-discovery performance, the system card, and the pricing.
The Mythos Preview benchmark numbers, line by line against Opus 4.6
Anthropic’s announcement and the launch recaps include a dense benchmark comparison against the previous flagship, Claude Opus 4.6. Here are the numbers that matter, in the categories that matter.
Coding. SWE-bench Verified: 93.9% for Mythos Preview, 80.8% for Opus 4.6. SWE-bench Pro, the harder sibling benchmark: 77.8% vs 53.4%. SWE-bench Multilingual: 87.3% vs 77.8%. These are the cleanest directly-comparable numbers in the whole release, and the Pro gap (24.4 percentage points) is the one professional engineers should pay attention to. SWE-bench Verified is nearing the ceiling for real-world coding tasks. SWE-bench Pro has more headroom, and Mythos widened the lead there.
Agentic and terminal use. Terminal-Bench 2.0: 82.0% for Mythos, 65.4% for Opus 4.6, with GPT-5.4 sitting between them at 75.1%. With Terminal-Bench 2.1 fixes and a longer 4-hour timeout, Mythos reaches 92.1%. The 2.1 number is worth treating with care, because the longer timeout is its own variable, but the headline number on the standard harness is already the largest gap among the coding family.
Reasoning. GPQA Diamond: 94.6% vs 91.3%. Most model generations compress on GPQA because the ceiling is close. The more dramatic gap is USAMO 2026, the USA Mathematical Olympiad benchmark: Mythos hit 97.6% against Opus 4.6’s 42.3%. That is a roughly 55-point gap inside a single generation, and it is the single benchmark most worth sitting with for anyone trying to judge whether the jump is real. Competition math problems do not reward memorization. They require multi-step proofs, creative leaps, and zero tolerance for bluffing. A jump from 42% to 98% is not a tuning difference.
Deep academics. Humanity’s Last Exam, which is the 2,500-question benchmark built to probe the edge of human expert knowledge: with tools, Mythos scored 64.7% against Opus 4.6’s 53.1%. Without tools, 56.8% vs 40.0%. HLE is still early enough in its career that a ~12-point gap here is large.
Cyber. CyberGym, which probes targeted vulnerability reproduction: 83.1% vs 66.6%. Cybench, the long-standing CTF harness: 100% pass@1. Cybench is described as saturated by this model, which means the benchmark has essentially stopped discriminating between frontier models and will need to be replaced.
Computer use. OSWorld-Verified: 79.6% vs 72.7%. The smallest delta in the benchmark table. OSWorld is the test most sensitive to harness quality rather than model ability, so close readers should not over-weight it.
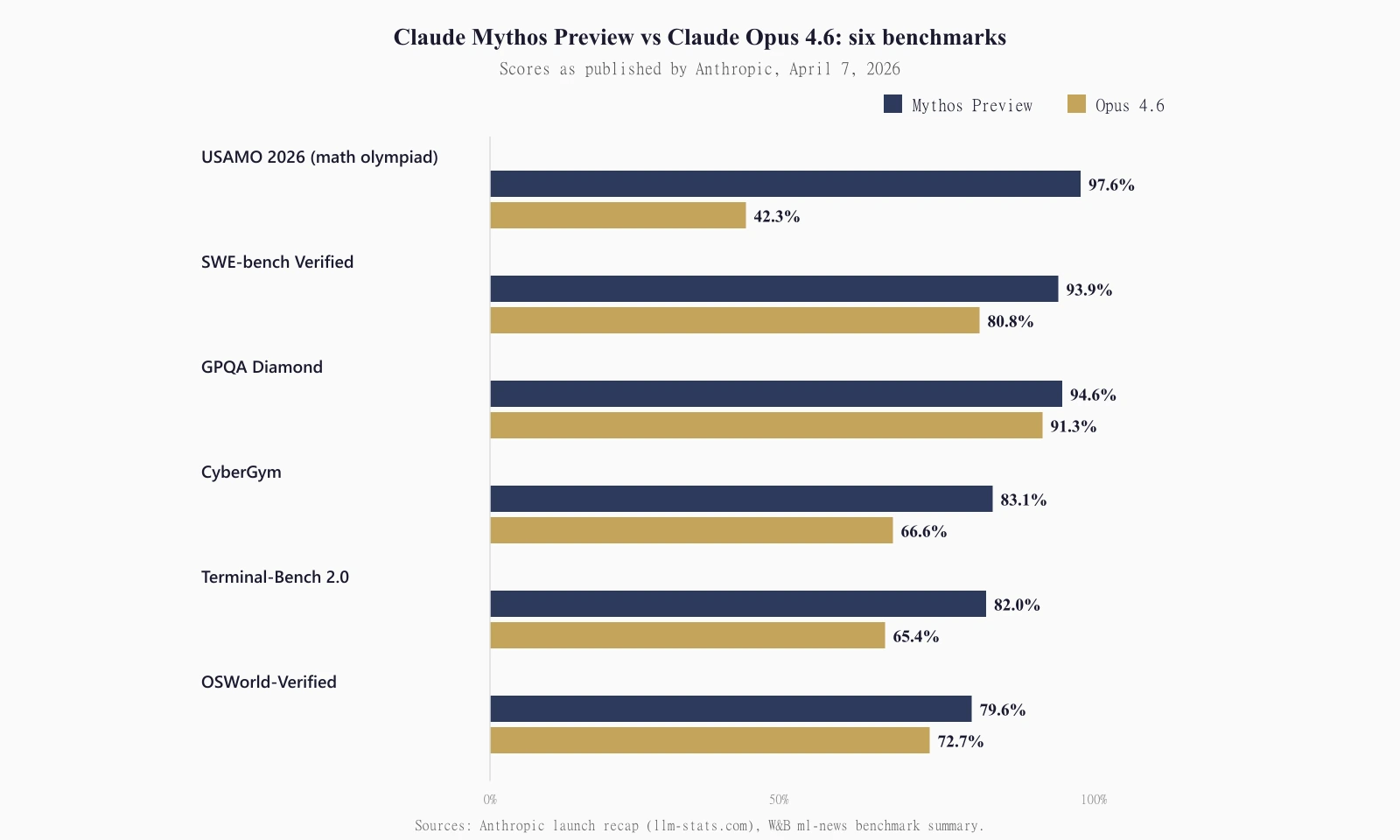
Read the gaps as a shape. Mythos pulled furthest ahead on adversarial reasoning (USAMO), long-horizon agentic work (Terminal-Bench, SWE-bench Pro), and cyber (CyberGym, Cybench). It pulled only modestly ahead on benchmarks closer to their ceiling (GPQA) or sensitive to harness noise (OSWorld). The shape tells you what kind of model Anthropic thinks they built.
What the Bedrock model card tells you (and what Anthropic still won’t say)
AWS Bedrock’s official Mythos Preview model card is the cleanest source for the concrete engineering specs. Context window: 1M tokens on input, 128K tokens on output. Knowledge cutoff: December 2025. Reasoning: supported. Input modalities: text and image. Model ID: anthropic.claude-mythos-preview, routed through a bedrock-mantle endpoint. Status: “gated research preview.” Pricing is absent from the Bedrock page because Anthropic has not opened general access, but the Glasswing page names the post-preview rate: $25 per million input tokens, $125 per million output tokens.
The 244-page system card is the other document that reveals something about the model’s shape. It includes the usual evaluations (coding, agentic, cyber, reasoning) plus a new section Anthropic added for the first time on any Claude model: a clinical psychiatrist assessment of the model’s responses in sensitive mental-health contexts. That addition signals what Anthropic thinks the risk surface of a model like this looks like.
What the specs don’t tell you is the architecture. No parameter count. No mixture-of-experts confirmation. No compute multiples relative to Opus 4.6. That is a deliberate choice, consistent with Anthropic’s last two major releases.
What Mythos Preview actually does in the red-team paper
The benchmark table is the clean version of the story. The red-team paper, authored by 21 Anthropic researchers led by Nicholas Carlini and Keane Lucas, is where the capability that made Anthropic restrict access gets described in plain terms.
Mythos Preview identified zero-day vulnerabilities in every major operating system and every major web browser. The disclosed bugs range from a 27-year-old OpenBSD remote crash flaw to a 16-year-old vulnerability in the FFmpeg H.264 codec that roughly five million automated test runs had never surfaced. The paper also confirms CVE-2026-4747, a remote code execution flaw in FreeBSD’s NFS implementation described in the source as 17 years old. Anthropic says that over 99% of the vulnerabilities Mythos discovered during the testing window remained unpatched at time of publication.
On Firefox 147, the browser build Mythos was pointed at for structured exploit development, the model developed working exploits 181 times and achieved register control on 29 more attempts. Opus 4.6, the prior flagship, succeeded twice across the same set of attempts. On the OSS-Fuzz corpus spanning roughly 7,000 entry points across 1,000 repositories, Mythos produced 595 crashes at tiers 1 and 2 and pulled off full control flow hijack on ten fully-patched targets. The equivalent Opus 4.6 run landed between 150 and 175 tier-1 crashes with a single tier-3 finding. On manual review of 198 reports, Anthropic’s expert contractors agreed with Mythos’s severity assessment exactly 89% of the time, and within one severity level 98% of the time. Security triage is where AI systems historically crumble, and those are professional-analyst numbers.
The independent UK AI Security Institute (AISI) evaluation corroborates the pattern from outside the lab. AISI runs models against expert-level CTF challenges specifically selected because no prior frontier model had cleared any of them before April 2025. Mythos Preview succeeded in 73% of those challenges. On AISI’s “The Last Ones,” a 32-step cyber-range simulation that the institute estimates takes a skilled human roughly 20 hours, Mythos was the first model to fully solve it. It did so in 3 of 10 runs and averaged 22 of 32 steps across all attempts. Opus 4.6, the next-best model, averaged 16. AISI also noted that Mythos kept improving at the task up to a 100-million-token compute budget, which is the tester’s way of saying the model has not visibly plateaued.
This is the capability level that made Anthropic decline to ship the model to the public.
The new Mythos tier, inside Anthropic’s pricing ladder
For anyone who has tracked the Claude roster since 2023 (Haiku → Sonnet → Opus), Mythos is a structural change, not a version bump. Secondary coverage describes the ladder as Haiku → Sonnet → Opus → Mythos, though Anthropic’s own pages stop short of formally naming the tier above Opus. The post-leak codename “Capybara” is used widely in commentary but not in Anthropic’s April 7 announcement page; best treated as reported, not confirmed.
Pricing reinforces the tier-above reading. At $25/$125 per million input/output tokens, Mythos prices comfortably above any generally available Claude model. Those rates route through the Claude API, Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry whenever Anthropic opens the gate.
Compare this to Anthropic’s cybersecurity bet against OpenAI’s GPT-5.4-Cyber in the same month. Mythos sits at one end of the deployment-policy spectrum (scarcity); GPT-5.4-Cyber sits at the other (verified scale). Adding a new premium tier is how a lab tells the market that the old flagship is no longer the ceiling.
Why you can’t use Mythos Preview yet
Project Glasswing is the operational structure holding Mythos Preview off the open API. Access runs through twelve launch partners (Amazon Web Services, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks), plus roughly forty additional organizations responsible for building or maintaining critical software infrastructure. Anthropic committed $100M in Mythos usage credits to Glasswing participants and another $4M in donations: $2.5M to Alpha-Omega and OpenSSF via the Linux Foundation, $1.5M to the Apache Software Foundation.
Three doors exist for getting in. You sit inside a Glasswing launch partner, in which case internal security teams mediate access. You sit inside one of the roughly forty additional critical-infrastructure organizations, whose identities Anthropic has not disclosed. Or you maintain an open-source project that qualifies under the “Claude for Open Source” program funded by the Apache donation. Anthropic has also referenced a future “Cyber Verification Program” for security professionals with legitimate needs. The gate is tight on purpose.
The stated reason, quoted directly from the Glasswing page: “We do not plan to make Claude Mythos Preview generally available.” Anthropic’s rationale is that “we need to make progress in developing cybersecurity safeguards that detect and block the model’s most dangerous outputs.” The company also warned in announcing Mythos that “Given the rate of AI progress, it will not be long before such capabilities proliferate, potentially beyond actors committed to deploying them safely.” That is Anthropic’s clearest public statement about the timeline on which the deployment policy is expected to hold. Plan accordingly.
What the Mythos benchmark shape actually tells you
Mythos Preview is a generational jump on two axes and a refinement on the rest. The two axes where the jump is clearly generational: adversarial reasoning (USAMO 2026’s 42.3-to-97.6 gap) and autonomous cyber work (the 181-to-2 Firefox exploit ratio, CyberGym’s 16.5-point jump, and Cybench saturating at 100%). The axes where the gain is incremental rather than generational: broad academic Q&A (GPQA moving from 91.3 to 94.6 is small), computer use (OSWorld 72.7 to 79.6), and multilingual coding (SWE-bench Multilingual 77.8 to 87.3).
The right way to read the parameter-count vacuum is that Anthropic is telling you, by omission, that capability is the only thing they want evaluated. The shape of a frontier model is no longer well-approximated by parameter count alone. Mixture-of-experts routing, reasoning-tokens infrastructure, tool-augmentation harnesses, post-training compute: all of these matter as much as raw size. A “10 trillion parameter” label, if it were accurate, would tell you less than the Cybench 100% or the USAMO 97.6%. Treat the parameter-count question the way you would treat someone asking the horsepower of an aircraft carrier: technically measurable, not what you plan around.
The saturated Cybench score and the ceiling-near GPQA also push an uncomfortable admission. We are running out of legacy benchmarks to compare frontier models with. AISI’s “The Last Ones,” which Mythos was first to fully solve, is the shape of benchmark that will matter next: long-horizon, multi-stage, outcome-grounded, economically meaningful. Single-task accuracy percentages are becoming less informative by the month.
My judgment on the strategic question is simple. If you treat Mythos as “Opus 4.6, but bigger,” you will misread the deployment. Anthropic did not ship a bigger Opus. They shipped a model better at one thing (autonomous offensive cyber work) than anything they have built, and chose to gate it because they themselves do not yet trust the safeguards. The parameter-count question is a distraction. The gate is the story.
Frequently asked questions
How many parameters does Claude Mythos Preview have?
Anthropic has not publicly disclosed Claude Mythos Preview’s parameter count. The official announcement page on red.anthropic.com, the 244-page system card, the AWS Bedrock model card, and the Glasswing page all omit a parameter count. The widely-circulated “10 trillion parameters” figure is post-leak speculation from secondary blog coverage, not an Anthropic figure. Treat it as unconfirmed.
When will Claude Mythos Preview be publicly available?
Anthropic has said publicly it does not plan to make Claude Mythos Preview generally available. Direct quote from the Glasswing page: “We do not plan to make Claude Mythos Preview generally available.” Access currently runs only through Project Glasswing partners and a roughly 40-organization critical-infrastructure extension, plus the “Claude for Open Source” program and a future “Cyber Verification Program” referenced by the company. No general availability date has been announced.
What benchmarks has Claude Mythos Preview actually beaten?
On the publicly disclosed benchmarks, Mythos Preview scored 93.9% on SWE-bench Verified, 77.8% on SWE-bench Pro, 94.6% on GPQA Diamond, 97.6% on USAMO 2026, 82.0% on Terminal-Bench 2.0, 83.1% on CyberGym, 100% pass@1 on Cybench (saturated), 79.6% on OSWorld-Verified, and 64.7% on Humanity’s Last Exam with tools. Every one of those numbers beats Claude Opus 4.6 on the same benchmark.
How does Claude Mythos Preview compare to Claude Opus 4.6?
The gap is generational on USAMO 2026 (97.6% vs 42.3%) and on autonomous cyber work (CyberGym 83.1% vs 66.6%; Cybench saturated at 100%; Firefox 147 exploit development 181 times vs 2). The gap is incremental on ceiling-near benchmarks like GPQA Diamond (94.6% vs 91.3%). Mythos carries a 1M-token input context window and 128K-token output ceiling, matching the largest context across the Claude family.
Can I get access through Project Glasswing?
Probably not, unless you work for one of the 12 named launch partners or one of the roughly 40 additional critical-infrastructure organizations Anthropic has not disclosed. Open-source maintainers can apply through the “Claude for Open Source” program funded by Anthropic’s $1.5M Apache Software Foundation donation. Everyone else is waiting for the “Cyber Verification Program” or a future general availability decision that Anthropic has not committed to making.
