
What do you do when your own model gets dangerously good at hacking? The two leading AI labs just answered with directly opposing strategies. Anthropic locked Claude Mythos Preview behind roughly 50 organizations. A week later, OpenAI shipped GPT-5.4-Cyber to thousands of verified defenders.
On April 7, 2026, Anthropic released Claude Mythos Preview only through Project Glasswing, a coalition of 11 external launch partners alongside Anthropic itself (Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks) plus roughly 40 additional organizations responsible for critical software infrastructure. On April 14, OpenAI launched GPT-5.4-Cyber through the top tier of its Trusted Access for Cyber program, scaling to "thousands of verified individual defenders and hundreds of teams responsible for defending critical software."
Both models can autonomously find and exploit software vulnerabilities, including zero-days. The disagreement is not about what the models can do. It is about who should be allowed to use them, and how the resulting risk gets managed.
Anthropic's bet is scarcity. Concentrate the most dangerous capability inside a tight perimeter, then pour $100M of usage credits into making sure Mythos finds bugs faster than attackers can. OpenAI's bet is verified scale. Ship a "cyber-permissive" model with a lower refusal boundary, gate it on identity, and put it in front of enough defenders that the wider ecosystem moves with it.
This is the cybersecurity industry's first real frontier-AI policy test. Here is what each side actually shipped.
| Claude Mythos Preview | GPT-5.4-Cyber | |
|---|---|---|
| Lab | Anthropic | OpenAI |
| Announced | April 7, 2026 | April 14, 2026 |
| Access program | Project Glasswing (closed invitation) | Trusted Access for Cyber (verified, tiered) |
| Reach | ~50 organizations (11 external launch partners plus ~40 critical-infrastructure orgs) | Thousands of verified individual defenders, hundreds of teams |
| Refusal stance | Standard safeguards | “Cyber-permissive” with a lower refusal boundary |
| Money committed | $100M usage credits plus $4M in open-source donations | $10M cybersecurity grant program (TAC at large) |
| Post-preview pricing | $25 / $125 per million input/output tokens (Claude API, Bedrock, Vertex AI, Microsoft Foundry) | Not disclosed |
| Design framing (per PYMNTS) | “Doesn’t assist security teams. It works independently.” | “Removes the friction security professionals hit when using standard AI tools.” |
The capability baseline: what Mythos and GPT-5.4-Cyber can both do
Before the strategic split, the technical baseline. Mythos and GPT-5.4-Cyber are the first frontier models that lab benchmarks describe as autonomously useful for offensive work, not just assistive.
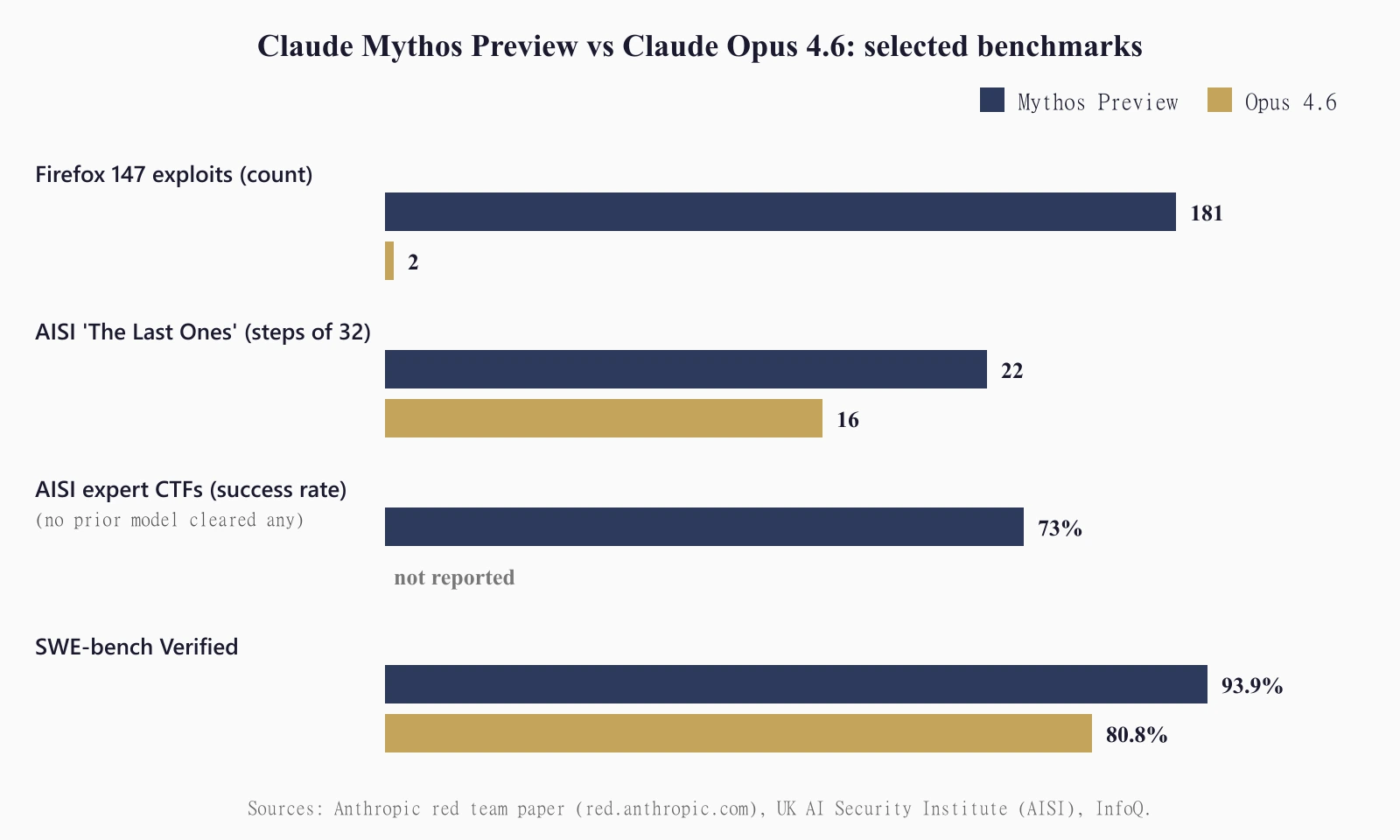
Anthropic's red-team paper, signed by Nicholas Carlini, Keane Lucas, and 19 other Anthropic researchers, says Mythos Preview identified zero-day vulnerabilities in every major operating system and every major web browser. Bugs ranged from a 27-year-old OpenBSD TCP SACK flaw to recently introduced ones. On a Firefox 147 vulnerability test, Mythos developed working exploits 181 times. Claude Opus 4.6, Anthropic's prior flagship, succeeded twice across the same set of attempts.
OSS-Fuzz tells the same story. Across roughly 7,000 entry points, Mythos produced 595 tier-1/2 crashes and full control flow hijack on ten separate targets. Opus 4.6 produced about 150 to 175 tier-1 crashes. On manual review of 198 reports, 89% of Mythos's severity assessments matched human reviewers exactly; 98% landed within one severity level. Anthropic's preview disclosed specific finds, including a 16-year-old vulnerability in the FFmpeg H.264 codec and CVE-2026-4747, a remote code execution flaw in FreeBSD's NFS implementation.
The UK AI Security Institute (AISI) ran an independent evaluation. Mythos cleared 73% of expert-level capture-the-flag challenges that no model had completed before April 2025. On AISI's "The Last Ones" cyber range, a 32-step attack simulation that AISI estimates takes a human roughly 20 hours, Mythos became the first model to fully solve it. It did so in 3 of 10 attempts and averaged 22 of 32 steps across all runs. Opus 4.6, the next-best model, averaged 16. AISI also noted that Mythos kept improving up to a 100M-token compute budget, which is to say it has not yet plateaued.
OpenAI has not released equivalent third-party benchmarks for GPT-5.4-Cyber. What the company has said is that the model adds binary reverse-engineering, letting security professionals analyze compiled software for malware potential, vulnerabilities, and security robustness without source-code access. Its companion product, Codex Security, has contributed to fixes on more than 3,000 critical and high-severity vulnerabilities since launch, across more than 1,000 open-source projects.
In other words, both labs now ship models that can do real offensive cyber work without a human in the loop. Neither side disputes that. The fight starts with what to do about it.
Anthropic's case for scarcity through Project Glasswing
Anthropic's framing is straightforward. The capability is too dangerous to deploy widely until the safeguards catch up. From the Glasswing announcement: "we need to make progress in developing cybersecurity safeguards that detect and block the model's most dangerous outputs."
Project Glasswing is the operational expression of that bet. The launch partner list reads like a who's-who of platform owners and critical-infrastructure operators: AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Roughly 40 more organizations sit behind that. Anthropic has not named them publicly, but the criterion is responsibility for critical software infrastructure.
The economics signal seriousness. Anthropic committed up to $100M in Mythos usage credits to Glasswing participants, plus $4M in donations: $2.5M to Alpha-Omega and OpenSSF via the Linux Foundation, $1.5M to the Apache Software Foundation. Once the preview ends, Mythos will run at $25 per million input tokens and $125 per million output tokens through the Claude API, Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry. Anthropic has not committed to general availability even at that price.
Translation: Anthropic is paying defenders to use Mythos against their own systems, on the theory that the lead time before equivalent capability shows up elsewhere is the window in which defenders need to find every old bug they can. Anthropic warned, in announcing Mythos, that "Given the rate of AI progress, it will not be long before such capabilities proliferate, potentially beyond actors committed to deploying them safely."
That sentence is the thesis. Mythos is not a product. It is a head start.
OpenAI's case for verified access at scale through TAC
A week later, OpenAI's answer arrived. GPT-5.4-Cyber is a fine-tune of GPT-5.4 with what OpenAI calls a "lower refusal boundary for legitimate cybersecurity work." The company also describes the model as "cyber-permissive." It adds binary reverse-engineering and is gated through Trusted Access for Cyber, the verification program OpenAI launched in February 2026 alongside a $10M cybersecurity grant.
The access numbers run an order of magnitude beyond Glasswing's. Where Anthropic capped Mythos at roughly 50 organizations total, OpenAI is scaling TAC to "thousands of verified individual defenders and hundreds of teams responsible for defending critical software." Individual researchers verify their identity at chatgpt.com/cyber. Enterprises route through an OpenAI sales rep. Approval slots applicants into a tiered access structure, and only the highest TAC tier unlocks GPT-5.4-Cyber itself. The point of the tiering is to do the policy work at the access layer rather than at the model layer, which is the precise opposite of what Anthropic chose with Mythos.
OpenAI's design rationale, read out of the announcement: cyber capability is dual-use, and the right gate is identity, not capability scarcity. If you can prove you are a defender, you should not have to fight a refusal model trained to be cautious for a general audience. PYMNTS distilled the contrast cleanly. GPT-5.4-Cyber is built to "remove the friction that security professionals hit when using standard AI tools," while Mythos "doesn't assist security teams. It works independently."
That line does more work than it looks. Anthropic's pitch is an autonomous offensive engine, deployed defensively, on a short leash. OpenAI's pitch is a power tool with a permissions check. Same capability bracket, different theory of who closes the gap.
The Codex Security number, 3,000+ critical and high-severity vulnerabilities fixed across 1,000+ open-source projects, is the proof point OpenAI keeps citing. The argument runs like this: if you want the ecosystem to harden, you need volume, and volume needs access. Forty organizations is a coalition. Thousands of verified defenders is a market.
Reading the Anthropic-OpenAI disagreement honestly
This is where the analysis lives, so let me be direct. Both sides have a real point, and both are also serving their own incentives.
Anthropic has spent two years positioning itself as the lab that takes capability risk most seriously. Glasswing is the most expensive and most operationally elaborate version of that brand it has shipped. The $100M credit pool, the open-source donations, the AISI evaluation, the Carlini-led red-team paper: these read together as a coordinated public statement that Anthropic will not be the lab that handed an autonomous exploit engine to whoever could pay for it. There is genuine risk substance here. There is also positioning.
OpenAI's argument has its own substance and its own positioning. The "thousands of verified defenders" framing turns scarcity into a competitive vulnerability. Mythos is locked up; GPT-5.4-Cyber is in your hands today. The lower-refusal design fixes a real pain point that working security researchers have complained about for two years: refusals on legitimate red-team work. And the Codex Security track record is concrete evidence that defender-side AI at scale produces measurable patch volume.
The honest read is that this is the first frontier-AI deployment where the two labs are not converging. Through 2024 and 2025, every major capability release looked roughly similar within months. Same model classes, same product surfaces, same pricing tiers. The cyber split is the first time the strategic question — who gets the dangerous capability — has produced visibly different answers.
Which one is the security community buying? The Dark Reading audience already telegraphed where the worry sits. A Dark Reading poll heading into 2026 found 48% of cybersecurity professionals identify agentic AI and autonomous systems as the single most dangerous attack vector for the year. That is not a poll about Mythos or GPT-5.4-Cyber specifically. But it is the room temperature these announcements landed into. Defenders already believe agentic offensive AI is the threat to plan around. The disagreement is whether to meet it with scarcity or with scale.
Costin Raiu, talking to PYMNTS, gave the version that should keep CISOs up at night. A model like Mythos, he said, would have "a field day" finding exploits in certain IBM systems powering finance. Whichever lab's policy you prefer, that is the underlying capability you are planning a defense around.
There is also a quieter point worth naming. Through 2024 and 2025, Anthropic and OpenAI competed primarily on capability and price. Cyber is the first domain where they have publicly disagreed on deployment policy in a way that affects who gets to use a frontier model at all. Expect that pattern to repeat in biology, in chemistry, and eventually in every domain where the model is plausibly more dangerous than the user it sits in front of. The Mythos versus GPT-5.4-Cyber split is the template, not the exception.
What the Mythos and GPT-5.4-Cyber split means for defenders in 2026
A few things are now true that were not true a month ago.
First, the question for any organization with a real attack surface has stopped being "should we use AI in our security program" and started being "which tier of access do we qualify for, and how fast." If you operate critical infrastructure or sit inside a Glasswing partner organization, Mythos is on the table and the time-cost of using it is being subsidized. If you are a security vendor, MSSP, or in-house red team, GPT-5.4-Cyber via TAC is the realistic ceiling on what you can put against your own systems this quarter. Almost everyone else sits downstream of one of those two streams.
Second, the bifurcation looks structural, not temporary. Mythos at $25/$125 per million tokens via Bedrock and Vertex is real pricing. Anthropic could open the gate. It is choosing not to. GPT-5.4-Cyber at thousands-of-defenders scale is also a deliberate ceiling, not a soft launch. Expect both ceilings to hold through 2026, which means defenders will spend the year evaluating two genuinely different procurement paths for "AI that can do offensive cyber work on our behalf."
Third, the threat side will use whatever leaks. Anthropic's own statement that capabilities will proliferate beyond actors committed to deploying them safely is honest. The window in which the Glasswing partners are finding old bugs in critical software is the same window in which equivalent capabilities show up in less-controlled releases, open-weight models, and stolen weights. Plan for both Mythos-class and GPT-5.4-Cyber-class capability hitting attacker workflows on a 12-to-18-month tail, regardless of which lab's policy holds.
The practical move for security leaders right now is unsexy: inventory the software you depend on, prioritize the parts that have not been seriously fuzzed in a decade, and start asking your vendors which AI tier they qualify for and what they are running it against. The Mythos partner list is a useful target list. If AWS, Microsoft, JPMorganChase, and Apple are racing the same model against their own code, the supply chain you depend on is about to get measurably better. Or, from the attacker's side, measurably more expensive to attack. Either way, the game changed in the second week of April.
Frequently asked questions
What is Claude Mythos Preview?
Claude Mythos Preview is Anthropic's most capable model so far. It scored 93.9% on SWE-bench Verified (versus 80.8% for Claude Opus 4.6) and shows autonomous offensive cyber capability, including discovering zero-day vulnerabilities in every major operating system and every major web browser. Anthropic released it on April 7, 2026, but only through Project Glasswing, a closed program of 11 external launch partners (alongside Anthropic itself) plus roughly 40 additional critical-infrastructure organizations.
What is GPT-5.4-Cyber?
GPT-5.4-Cyber is a fine-tune of GPT-5.4 that OpenAI describes as "cyber-permissive." It has a lower refusal boundary for legitimate cybersecurity work and adds binary reverse-engineering capabilities. OpenAI announced it on April 14, 2026 and gates access through the highest tier of the Trusted Access for Cyber program, which OpenAI is scaling to thousands of verified defenders and hundreds of security teams.
Can I get access to either model?
Probably not Mythos. Anthropic has not announced any public availability, and Glasswing membership is restricted to organizations responsible for critical software infrastructure. GPT-5.4-Cyber is reachable if you can pass OpenAI's identity verification: individuals start at chatgpt.com/cyber, enterprises request team access through an OpenAI representative. Approval routes you into the appropriate TAC tier, and the highest tier is required for GPT-5.4-Cyber itself.
Are these models more dangerous than ChatGPT or Claude Opus 4.6?
For offensive cyber work, yes, by a wide margin. AISI found Mythos clears 73% of expert-level CTFs that no prior model had solved, and on the "The Last Ones" 32-step cyber range Mythos averaged 22 steps versus 16 for Opus 4.6. The 181-vs-2 Firefox exploit gap between Mythos and Opus 4.6 is the cleanest illustration of the jump. OpenAI has not published comparable benchmarks for GPT-5.4-Cyber, but the model is explicitly designed to refuse less on cybersecurity tasks, which means it will produce usable output on requests its predecessors blocked.
What should organizations do to prepare?
Three things. One: inventory your critical software dependencies and ask each vendor which AI cybersecurity tier they qualify for and what they are running it against. Two: assume that capabilities at this level will proliferate beyond Glasswing and TAC on a 12-to-18-month tail (Anthropic's own framing), and harden accordingly. Three: if you are a defender who would meaningfully benefit from GPT-5.4-Cyber access, start the TAC verification process now. The lower tiers of the program were already running before this announcement, and the queue is only going to get longer.
