
On Tuesday, April 14, 2026, OpenAI did the loudest thing it could do in response to Anthropic's Claude Mythos Preview. It did not lock a cybersecurity-capable model behind a vault door and hand the key to a dozen hand-picked partners. It built a turnstile, pointed at anyone who can prove they are a defender, and started letting the line move.
The product is GPT-5.4-Cyber. The program behind it is Trusted Access for Cyber, or TAC. The bet is the most interesting thing OpenAI has said out loud about how frontier AI should ship into a cyber environment: that verifying who gets access is more defensible than restricting what the model can do.
What GPT-5.4-Cyber is, in one paragraph
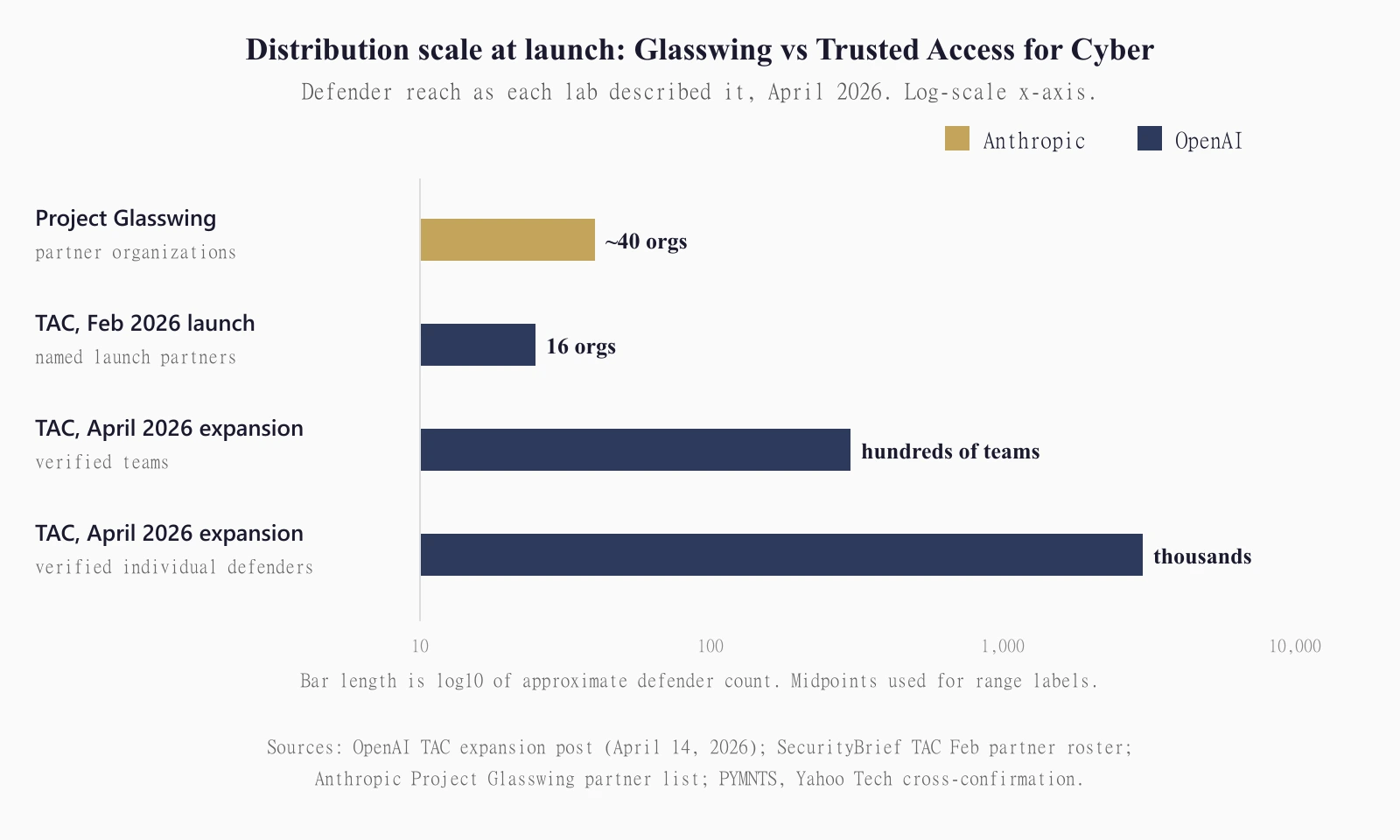
GPT-5.4-Cyber is a variant of GPT-5.4 that OpenAI has fine-tuned to be "cyber-permissive." It keeps the base model's capabilities and lowers the refusal boundary for legitimate cybersecurity work. Its headline new capability is binary reverse engineering: analyzing compiled software for malware, vulnerabilities and security robustness without source code. OpenAI announced it on April 14, 2026 as part of an expansion of Trusted Access for Cyber, the identity-verified program it originally introduced in February 2026. Access is tiered. Individual defenders verify at chatgpt.com/cyber; enterprises apply through an OpenAI account representative. Only the highest tier unlocks GPT-5.4-Cyber itself. At the April 14 announcement, OpenAI said TAC was scaling to "thousands of verified individual defenders and hundreds of teams responsible for defending critical software."
That single paragraph is the entire model, distilled. Everything below is how the pieces actually fit.
| Dimension | OpenAI TAC / GPT-5.4-Cyber | Anthropic Project Glasswing / Claude Mythos |
|---|---|---|
| Announced | April 14, 2026 (TAC launched Feb 2026) | April 7, 2026 |
| Base model | GPT-5.4, fine-tuned as GPT-5.4-Cyber | Claude Mythos Preview (net-new model tier) |
| Access philosophy | Verify the defender, not the capability | Restrict the capability to verified partners |
| Reach at launch | Thousands of individuals, hundreds of teams | ~40 partner organizations |
| How you qualify | Identity verification, KYC, tier application | Selected launch partner or Glasswing cohort |
| Signature capability | Binary reverse engineering, lowered refusal boundary | Novel zero-day discovery in browsers and OSes |
| Risk framing | High cyber capability under Preparedness Framework | Held back from general release as too capable |
| Money committed | $10M cybersecurity grant program (Feb 2026) | Up to $100M in Glasswing usage credits |
What the model actually does
Strip out the marketing language and there are three concrete changes versus standard GPT-5.4.
The first is binary reverse engineering. Security analysts often work without source code. Malware samples arrive as executables. Closed-source vendor code has to be vetted. Supply-chain investigations hit compiled artifacts whose provenance is the whole point of the investigation. GPT-5.4-Cyber is tuned to handle that workflow directly. The OpenAI blog describes it as "binary reverse engineering capabilities that enable security professionals to analyze compiled software for malware potential, vulnerabilities and security robustness without needing access to its source code." That is the new muscle.
The second is the refusal boundary. The standard GPT-5.4 deployment refuses a long tail of queries that overlap with offensive security: detailed exploit chains, specific vulnerability classes in named software, techniques that read as dual-use the instant a classifier looks at them. A red teamer writing a Ghidra-powered analysis prompt does not want the model to stop at the word "exploit." GPT-5.4-Cyber "lowers the refusal boundary for legitimate cybersecurity work," in OpenAI's own phrasing. That does not mean the model is jailbroken. It means the model now trusts context that standard GPT-5.4 would not.
The third is malware analysis proper. OpenAI's description (malware potential, vulnerabilities, security robustness of compiled artifacts) reads as a pitch to the SOC analyst and the threat-intel researcher, not to the casual chat user. The workflow is continuous: feed a binary, get structural analysis, suspected capability, indicators, and reasoning you can hand to an analyst.
A useful sanity check on capability trend: on the Professional Capture-the-Flag (CTF) evaluation, OpenAI's Codex family jumped from around 27% on GPT-5 to 76% on GPT-5.1-Codex-Max. CVE-Bench went from 53% to 80% across the same stretch. OpenAI has not yet published GPT-5.4-Cyber's own scores on those evals, but the trajectory is where the model lives.
Trusted Access for Cyber, explained
TAC is the whole story. The model is the piece you can publish. The verification funnel is the piece that has to work if the model is going to ship at scale without becoming the proliferation event Anthropic has been publicly nervous about.
Here is how the funnel is structured, per OpenAI's own documentation and the outlets that reproduced it verbatim.
Individuals verify identity at chatgpt.com/cyber. Enterprises apply through an OpenAI account representative. OpenAI uses, in its words, "strong KYC and identity verification" plus objective criteria to decide who qualifies. Approved uses cluster around three buckets: security education, defensive programming, and responsible vulnerability research. Existing TAC customers who want GPT-5.4-Cyber have to step up to a higher tier of authentication, not just ask nicely.
The February 2026 launch cohort is a who's-who of finance, critical infrastructure and the major security vendors: Bank of America, BlackRock, BNY, Citi, Cisco, Cloudflare, CrowdStrike, Goldman Sachs, iVerify, JPMorgan Chase, Morgan Stanley, NVIDIA, Oracle, Palo Alto Networks, SpecterOps and Zscaler. Government evaluators named in TAC materials include the U.S. Center for AI Standards and Innovation and the UK AI Security Institute. GPT-5.4-Cyber is not currently available to U.S. government agencies; access is under discussion through governance and safety review.
Four of TAC's February partners (Cisco, CrowdStrike, JPMorgan Chase and NVIDIA) also appear on Anthropic's Project Glasswing launch-partner list. Read that again. The same four companies are getting Anthropic's "we are keeping this behind a vault door" model and OpenAI's "verified defenders should be able to use this at scale" model at once. If you wanted a live comparison of which philosophy produces more defender utility, those four companies are running it whether they wanted to or not.
Alongside the original February TAC announcement, OpenAI launched a $10 million cybersecurity grant program. Named recipients in the launch round include Socket and Semgrep in the software-supply-chain category and Calif and Trail of Bits on the frontier-AI-plus-vulnerability-research side. These are credits, not cash. But the message is that OpenAI is underwriting the kind of defender work the model is designed to accelerate.
One constraint worth naming: Zero-Data Retention. Customers who run ChatGPT in ZDR environments lose some of the GPT-5.4-Cyber envelope. OpenAI's reasoning, reported by PYMNTS and Help Net Security, is straightforward: without retention, OpenAI has less visibility into how the model is being used, which matters more for a cyber-permissive variant than for a standard model. Security organizations that need ZDR for legal or regulatory reasons can still use TAC; they just get less of the loosened guardrails.
The Codex Security context
TAC did not appear from nowhere. OpenAI has been publishing cyber-adjacent work for long enough that GPT-5.4-Cyber reads as the natural output of a program, not a reactive launch.
Codex Security, OpenAI's AI application-security agent, is the most concrete artifact of that program. It has been in research preview and, per OpenAI's own accounting, has contributed to fixes for "more than 3,000 critical and high-severity vulnerabilities" since launch. Codex for Open Source, the free-scan arm aimed at open-source maintainers, has reached more than 1,000 projects. These are defender numbers. They are not benchmarks designed to look good at a launch.
Under OpenAI's Preparedness Framework, GPT-5.3-Codex was the first model the company classified as high capability for cybersecurity. OpenAI's April 14 post tells us it is now "planning and evaluating future releases as though each new model could reach 'High' levels of cybersecurity capability." Translation: the Preparedness Framework stopped being a classifier waiting to trip on a specific model and started being the default assumption for anything that ships.
That framing matters when reading GPT-5.4-Cyber. The model is not arriving into a regulatory vacuum. It is arriving into a framework OpenAI has already designed, with an identity program that was live for two months before the model shipped, attached to a grant program that seeded the defender ecosystem before the most permissive variant was offered.
How it compares to Claude Mythos, briefly
Anthropic and OpenAI made opposing bets on the same question.
The full Claude Mythos vs GPT-5.4-Cyber breakdown walks through the benchmarks, the red-team evaluations, and the deployment-policy split in depth. The short version is that Anthropic built Project Glasswing around the idea that a cyber-capable frontier model is a proliferation risk by default, so the answer is to restrict access to a few dozen organizations whose defensive use is contractually bound. OpenAI built TAC around the idea that the risk is asymmetry (offense outpacing defense because defenders do not have access to the best tools), so the answer is to verify the defender and let the defender population scale.
Neither bet is obviously wrong. They just disagree on what the threat model is. Anthropic is solving for "what if this model ends up in the hands of a state-sponsored actor." OpenAI is solving for "what if the defender at the regional bank cannot use a frontier model to vet a third-party binary." Both are live problems.
Who qualifies, and who doesn't
The access criteria, read directly:
- Individual security researchers, penetration testers, red teamers, SOC analysts and academic researchers can verify identity at chatgpt.com/cyber. They enter a queue for verification and tier placement.
- Enterprise security teams (in-house SOCs, consultancies, managed security vendors) apply through an OpenAI account representative. The application is organizational, not per-user.
- Existing TAC customers can apply for higher tiers. The highest tier unlocks GPT-5.4-Cyber. Lower tiers get reduced friction on existing models.
- Government agencies, at least on the U.S. side, are currently not approved. OpenAI says it is in ongoing discussions about access through governance and safety review.
- Deployments inside strict Zero-Data Retention environments get a reduced version of the capability envelope, because OpenAI loses context and intent visibility in ZDR mode.
The gate is real. OpenAI is explicit that the rollout is "a limited, iterative deployment to vetted security vendors, organizations, and researchers." The "thousands of individuals" number is a destination, not a day-one state. What shipped on April 14 is the program at a usable scale, not an open floodgate.
The strategic bet, read honestly
I have been building AI systems in production long enough to be skeptical of access-control stories that promise to be both safe and scalable. TAC is the first one I have seen from a frontier lab that looks like it could actually be both.
The insight OpenAI's approach is leaning on is boring and correct: the defender population is not one blob, and treating it as one blob is how you end up with a three-lab oligopoly where the best cyber tooling sits inside ten companies. A community bank's security lead is a defender. A malware analyst at a regional MDR is a defender. A maintainer of an open-source library with two million downloads a week is a defender. None of them is on Anthropic's Project Glasswing partner list. All of them have the same problem: they need a model that stops refusing when they hand it a binary.
That is the analogy I keep coming back to. Anthropic's model of "a few trusted partners" looks a lot like the pharmaceutical model — narrow, contractual, high-control. OpenAI's TAC model looks more like a licensed profession: you prove you are who you say you are, you accept the code of practice, you get tooling proportionate to your tier. The pharmaceutical model works for molecules whose physical distribution is the risk. For software that can be duplicated infinitely, "control who has it" degrades the moment one Glasswing partner has a bad week. Licensing a population, versus licensing a product, is the older idea that happens to scale.
The obvious critique of TAC is not that it is unsafe. It is that it may be less honest than it looks. Fouad Matin, a cyber researcher at OpenAI, put the philosophy plainly: "This is a team sport, we need to make sure that every single team is empowered to secure their systems. No one should be in the business of picking winners and losers when it comes to cybersecurity." The problem is, a tiered verification system is the business of picking winners and losers. It just does it through identity criteria instead of negotiated contracts. Whether those criteria are well-designed will be the entire story in six months.
Marcus Fowler, CEO of Darktrace Federal, offered the honest operational caveat: "faster analysis does not automatically translate to faster risk reduction." A SOC that gets a 10x speedup on binary triage still cannot patch faster than its change-management window lets it. GPT-5.4-Cyber solves the analysis bottleneck. It does not solve the organizational bottleneck behind the analysis bottleneck. That is true, and it is not a reason to dismiss the model. It is a reminder that capability is one input to defender effectiveness, not the whole story.
The bet I would make, watching this play out, is that TAC's distribution model will dominate within 18 months not because it is safer than Glasswing but because the set of organizations that actually ship defensive security work is much larger than the 40-ish lab-picked partners any single company can manage. If Glasswing's concentration is right, OpenAI has a proliferation problem. If OpenAI's breadth is right, Anthropic has a relevance problem. Both cannot be right. The honest answer is that we are going to find out.
Frequently asked questions
What exactly is GPT-5.4-Cyber?
GPT-5.4-Cyber is a variant of OpenAI's GPT-5.4 fine-tuned for defensive cybersecurity. It keeps the base model's reasoning and coding capability and lowers the refusal boundary for legitimate cybersecurity work. Its signature new capability is binary reverse engineering: analyzing compiled software for malware potential and vulnerabilities without source code access.
When did GPT-5.4-Cyber launch, and who has access?
OpenAI announced GPT-5.4-Cyber on April 14, 2026 as an expansion of its Trusted Access for Cyber program. The program launched in February 2026. The April 14 expansion scales access to "thousands of verified individual defenders and hundreds of teams responsible for defending critical software." Only the highest TAC tier unlocks GPT-5.4-Cyber itself.
How do I apply for Trusted Access for Cyber?
Individual security researchers verify identity at chatgpt.com/cyber. Enterprises apply through an OpenAI account representative. OpenAI uses KYC and objective criteria (including your role, your employer, and stated defensive use cases) to decide tier placement. Existing TAC customers can apply for higher tiers, including the one that unlocks GPT-5.4-Cyber.
How is this different from Claude Mythos Preview?
Claude Mythos Preview is Anthropic's most capable model, shipped through a restricted program (Project Glasswing) with approximately 40 partner organizations. GPT-5.4-Cyber is a cyber-permissive fine-tune of GPT-5.4, shipped through an identity-verified program that reaches thousands of individuals and hundreds of teams. Anthropic bet on restricting the capability; OpenAI bet on verifying the defender. For benchmarks and red-team numbers, see our deep dive on the Anthropic-OpenAI cybersecurity split.
Does GPT-5.4-Cyber have a published system card with benchmark scores?
Not yet, at least not one that is specific to GPT-5.4-Cyber as distinct from the underlying GPT-5.4. The capability claims are qualitative (lowered refusal boundary, binary reverse engineering), not yet backed by a public scorecard. Earlier OpenAI Codex models do have published cyber numbers: the family moved from 27% on Professional CTF (GPT-5) to 76% (GPT-5.1-Codex-Max), and from 53% to 80% on CVE-Bench over the same generations. GPT-5.4-Cyber sits downstream of that trajectory.
