
Gemini 3.1 Pro holds or shares the top score on most public AI benchmarks right now. It also costs a fraction of its closest competitor. Both facts are true. Both need context, because neither tells the whole story.
The short answer, in real numbers
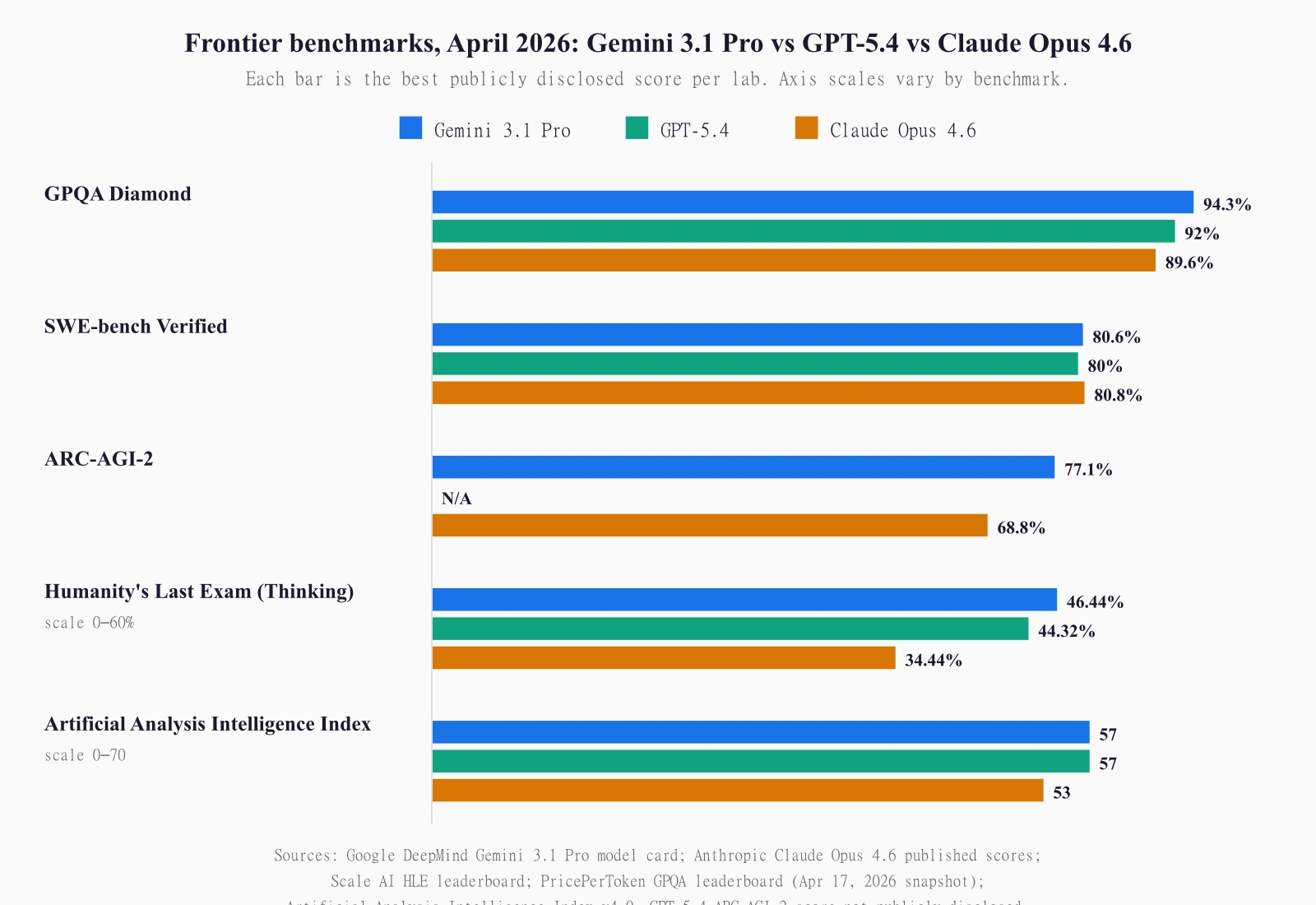
Gemini 3.1 Pro Preview launched on February 19, 2026. On Google DeepMind's own model card it lists: GPQA Diamond 94.3%, ARC-AGI-2 77.1%, SWE-bench Verified 80.6%, MMMU-Pro 80.5%, Humanity's Last Exam 44.4% (text + multimodal, no tools), MMMLU 92.6%, Terminal-Bench 2.0 68.5%, LiveCodeBench Pro 2887 Elo, and MRCR v2 84.9% at 128k context. On the Artificial Analysis Intelligence Index, the most-watched composite score in the industry, Gemini 3.1 Pro Preview sits at 57, tied with GPT-5.4 and four points clear of Claude Opus 4.6 at 53. It leads 6 of the 10 evaluations that feed into that index.
The price tag is the other half of the story. Gemini 3.1 Pro runs at $2 per million input tokens and $12 per million output tokens for prompts up to 200K. That's cheaper than Claude Opus 4.6's $5 input and $25 output, and cheaper than GPT-5.4's $2.50 and $15. Running the full Intelligence Index evaluation cost Artificial Analysis $892 on Gemini 3.1 Pro, and $2,486 on Claude Opus 4.6 at max reasoning. Same ceiling. Less than half the bill.
The part people are skipping: on LMArena's vote-based leaderboard, Gemini is not #1. On SWE-bench Verified, Gemini is not #1. On FrontierMath, the record still belongs to Gemini 3 Pro, not 3.1. The composite crown is real. The "best at everything" framing is not.
| Benchmark | Gemini 3.1 Pro | GPT-5.4 | Claude Opus 4.6 | Leader |
|---|---|---|---|---|
| GPQA Diamond | 94.3% | 92.0% | 89.6% (Thinking) | Gemini 3.1 Pro |
| SWE-bench Verified | 80.6% | ~80% | 80.8% | Claude Opus 4.6 |
| ARC-AGI-2 | 77.1% | Not published | 68.8% | Gemini 3.1 Pro |
| Humanity’s Last Exam (Thinking) | 46.44% | 44.32% (Pro) | 34.44% (Max) | Gemini 3.1 Pro |
| Artificial Analysis Intelligence Index | 57 | 57 | 53 | Tied (Gemini / GPT-5.4) |
| LMArena Elo (April 2026) | ~1493 | ~1484 | ~1504 (Thinking) | Claude Opus 4.6 |
| Input price per 1M tokens | $2.00 | $2.50 | $5.00 | Gemini 3.1 Pro |
| Output price per 1M tokens | $12.00 | $15.00 | $25.00 | Gemini 3.1 Pro |
GPQA Diamond, explained and scored
GPQA Diamond is 198 graduate-level questions in biology, chemistry, and physics, written by domain PhDs and deliberately made "Google-proof." A human non-expert with the internet scores roughly 34%. A PhD in the relevant field scores about 65%. So when a frontier model clears 90%, it has closed the expert-plus gap on multiple-choice science.
Google's own Gemini 3.1 Pro model card lists 94.3% on GPQA Diamond with no tool use. That is the highest score any proprietary model has publicly posted as of this writing. The PricePerToken benchmark leaderboard, sourcing its data from Artificial Analysis, shows the ranking a different way: Gemini 3.1 Pro Preview at 94.1%, GPT-5.4 at 92.0%, Claude Opus 4.6 Thinking at 89.6%. The 0.2-point Gemini variance between Google's card and the third-party harness is the kind of thing you see whenever two different runs measure the same model. Methodology, temperature, thinking budget, all of it drifts. The direction doesn't drift. Gemini leads.
Two caveats worth keeping in mind. First, GPQA Diamond is saturating. When a benchmark is this close to 100, half a percentage point is sometimes one hard question, and "leader" can swap on a single prompt template. Second, strong GPQA does not imply strong science reasoning in open-ended settings. It implies strong multiple-choice pattern matching on graduate science. Both things can be true.
Humanity's Last Exam: the harder test that Gemini also leads
Humanity's Last Exam was designed to fix the GPQA problem. Its 2,500 questions span every serious subject domain, they are multimodal, and they were curated specifically to be the kind of question that still trips up frontier models. The point is to keep running after GPQA flatlines at the ceiling.
On HLE with no tools, Gemini 3.1 Pro scored 44.4% per Google's model card. On Scale AI's Humanity's Last Exam leaderboard, which accepts thinking-mode submissions, Gemini 3.1 Pro Thinking High currently holds #1 at 46.44% (±1.96), with GPT-5.4 Pro in second at 44.32% (±1.95), and Claude Opus 4.6 Thinking Max further back at 34.44% (±1.86). The Gemini number moved roughly ten points in the six months since Gemini 3 Pro's 37.52%. That is a lot of ground for a benchmark that was meant to hold up for years.
The honest caveat is calibration. Scale AI reports Gemini 3.1 Pro at a calibration error of 51, versus GPT-5.4 Pro at 38. Translation: Gemini is more likely to sound confident when it is wrong. On a benchmark where you can only get credit for answers you are certain about, GPT-5.4 plays the hedging game better. Gemini plays the ceiling game better. Different trade-offs, and the benchmark does not punish the right one.
LMArena Elo: where Gemini is not #1
Worth stating plainly, because it gets skipped in every Gemini 3.1 Pro launch summary: on LMArena, as of April 2026, Claude Opus 4.6 Thinking sits at #1 with an Elo around 1504. Gemini 3.1 Pro Preview is #3 at roughly 1493. GPT-5.4 High is near 1484. Nine Elo points separate the top three.
This matters because LMArena is the one major benchmark that nobody in any of the three labs controls. It's blind human voting on head-to-head model outputs. When Anthropic trains Opus to be sharper at pairwise comparisons (more helpful-feeling, cleaner formatting, better at refusing cleanly), the Arena picks that up faster than any internal eval does. Gemini leads the composite. Opus leads the vote.
The two leaderboards measure different things. The Intelligence Index rewards depth of reasoning, hard-problem math, and agentic follow-through. Arena rewards whatever the median user thinks "better" means on whatever question they felt like typing. Both are real signals. Neither is the whole model.
FrontierMath and the reasoning ceiling
FrontierMath is Epoch AI's research-math benchmark. Tier 4 is where PhD mathematicians go to die. When Gemini 3 Pro launched in November 2025, Epoch posted on X that it had set a new record: 38% on Tiers 1–3, 19% on Tier 4, and an Epoch Capabilities Index score of 154, up from GPT-5.1's prior 151. That was the real news. FrontierMath Tier 4 had been stuck under 10% for over a year.
Then Gemini 3.1 Pro arrived and Epoch published an understated follow-up note: Gemini 3.1 Pro scored "comparably" to Gemini 3 Pro on FrontierMath. The record did not move. What did move was a Tier 4 problem that no prior model had cracked. Gemini 3.1 Pro solved it, though Epoch specifically noted the solution was "not how a human would" get there.
Sit with that for a second. The top line didn't change, but the model found a novel path through a problem that had defeated every predecessor. This is the pattern you now see across frontier evaluations: the headline number plateaus while the underlying capability bleeds sideways into categories the benchmark wasn't tracking. If you were looking at the tier averages alone, you would conclude 3.1 Pro is a routine dot release. If you were looking at solved-for-the-first-time problems, you would conclude something else entirely.
Where Gemini 3.1 Pro is NOT the leader
SWE-bench Verified, the benchmark developers actually care about, is the cleanest example. It takes real GitHub issues from mature open-source repositories and asks whether the model can close them. Gemini 3.1 Pro posts 80.6%. Claude Opus 4.6 posts 80.8%. The gap is 0.2 percentage points, well within run-to-run noise, but the order matters. Google has not unseated Anthropic on the benchmark that maps most cleanly to what working engineers do.
Zoom out on coding and the picture gets more interesting, not less. LiveCodeBench Pro is where Gemini 3.1 Pro pulls ahead hard: 2887 Elo on competitive programming, well above Gemini 3 Pro's 2439 and GPT-5.2's 2393. SWE-bench Pro, a harder agentic coding harness, puts Gemini at 54.2%. Respectable, but not the leader either. Different coding benchmarks, different winners. That is the useful framing for anyone picking a model for a real coding stack rather than a PR chart.
I'd put it this way. If your workload looks like "write a clever algorithm from a spec," Gemini 3.1 Pro is the sharpest. If your workload looks like "navigate a real repository, touch the right files, ship a patch that survives CI," Claude Opus 4.6 still edges it. The composite crown and the coding crown are not the same crown, and anyone selling you a single leader chart is selling you narrative, not data.
What the composite scores miss
The Intelligence Index is composed of ten evaluations: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond, and CritPt. A 57-tied score means Gemini and GPT-5.4 arrived at the same composite through different paths. Gemini leads 6 of 10 evaluations. GPT-5.4 leads the other 4. At the aggregate, they meet.
Decomposing the index matters because it changes how you read "tied." On reasoning-heavy and research-science-heavy evals (HLE, GPQA Diamond, CritPt), Gemini wins. On some of the agentic and tool-use evals, GPT-5.4 wins. The index is doing its job, capturing that frontier intelligence is now a vector, not a scalar. But the vector points in genuinely different directions for each model. If your use case sits mostly in one region of that vector, the composite is lying to you by averaging.
Google's launch post said Gemini 3.1 Pro leads 13 of 16 benchmarks. That figure comes from a Google-selected benchmark basket, and it is worth noting that SmartScope ran the numbers and found GPT-5.3-Codex had only published scores for 2 of those 16. In the other 14, Gemini was "winning" against an absent competitor. Not fraud. Just the PR chart tic every lab does. Check the footnotes before you let the headline bar graph set the frame.
The pricing angle: cheapest frontier, by a wide margin
Let's put the prices next to each other. Gemini 3.1 Pro charges $2 per million input tokens and $12 per million output tokens (≤200K context). GPT-5.4 charges $2.50 and $15 for the same tier. Claude Opus 4.6 charges $5 and $25. Side by side:
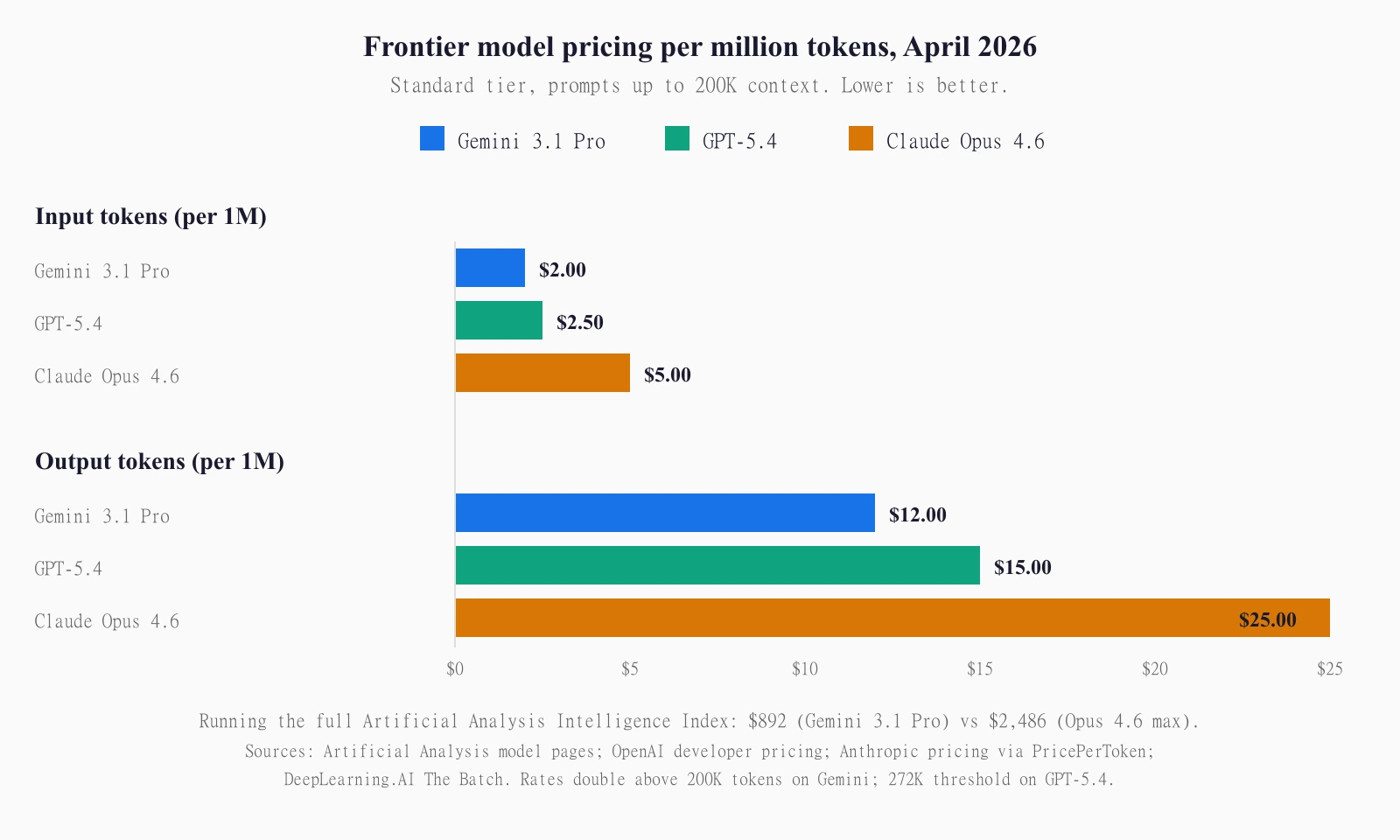
Per-token, Gemini is 20% cheaper on input than GPT-5.4 and 20% cheaper on output. Against Claude Opus 4.6, Gemini is 2.5× cheaper on input and roughly 2.08× cheaper on output. At frontier quality, there is no previous moment where one of the three labs put the top-of-stack model at the bottom of the pricing stack. That is the actual news of this launch. Not the benchmark leadership, which is shared.
Running the full Intelligence Index, all ten evaluations end-to-end, cost Artificial Analysis $892 on Gemini 3.1 Pro. The same evaluation cost $2,486 on Claude Opus 4.6 at max reasoning, $2,304 on GPT-5.2. That's a 64% cost reduction against Claude Opus 4.6 at max reasoning, the next-closest frontier on composite intelligence. At production scale across millions of queries, that gap is the difference between a feature that ships and a feature that gets killed in the margin review.
The context window matters too. Gemini 3.1 Pro ships with 1M input tokens and a 64K output ceiling. Pricing doubles once you cross 200K in a prompt, which is important to model if your product lives in long-context territory. At sub-200K, the effective cost advantage against both competitors is clean. Above 200K, Gemini's $4 input and $24 output put it roughly even with GPT-5.4's standard tier and still cheaper than Claude Opus 4.6.
So what actually changed with 3.1
Gemini 3.1 Pro is not a radical architectural step from 3 Pro. Epoch AI's FrontierMath note makes that explicit: the math ceiling did not move. What moved is the breadth of capability at a given inference cost. Google describes the model as "a smarter, more capable baseline" and says it is "designed for tasks where a simple answer isn't enough." Translate: same price, more reasoning depth, better agentic and multimodal behavior.
The way to think about 3.1 is not "new frontier." It's "compressed frontier." The same capability layer, delivered cheaper and with more stability under long prompts and thinking modes. Thinking mode is now a first-class control across all three frontier labs. Gemini ships Low, Medium, and High thinking budgets on the API. GPT-5.4's API exposes five reasoning-effort tiers from none to xhigh. Claude Opus 4.6 separates Thinking from Thinking Max. Each setting moves benchmark scores by several points and adds real latency and token cost. The benchmark numbers in this piece are from the highest practical thinking configurations each lab published, which is the apples-to-apples way to read them. A user who leaves their model on a low thinking default will never touch these ceilings. For a preview release, that is a reasonable claim to earn. For a preview release that ties the Intelligence Index at a 57% discount against Opus, it is a meaningful commercial event.
If the Claude Opus 4.6 launch earlier in February was "Anthropic shows up swinging on ARC-AGI-2," and the GPT-5.4 release in March was "OpenAI reclaims the reasoning-index lead at premium pricing," then Gemini 3.1 Pro is "Google ties the top at the budget tier." Three different moves. Same quarter. Anyone who tells you the race is settled is reading yesterday's chart.
For related context on this sprint: the Anthropic side of the race, including the Claude Mythos Preview and its parameter disclosures, lives in the Mythos parameters and benchmark breakdown. The cybersecurity split between GPT-5.4-Cyber and Claude Mythos sits next to this same commercial story from a different angle. OpenAI's Trusted Access for Cyber program explains how the verification gates work for the other half of this race.
Frequently asked questions
Is Gemini 3.1 Pro the best AI model right now?
Depends on the axis. On the Artificial Analysis Intelligence Index, it is tied for the top at 57, matching GPT-5.4. On LMArena's human vote, it ranks third, behind Claude Opus 4.6 Thinking. On GPQA Diamond and ARC-AGI-2, it leads. On SWE-bench Verified, it trails Claude Opus 4.6 by 0.2 points. There is no single ranking that says "best." There are multiple rankings that say "at the top."
What is Gemini 3.1 Pro's GPQA Diamond score?
94.3% according to Google's official model card, with no tools used. PricePerToken's leaderboard, sourcing from Artificial Analysis, lists it at 94.1%. Either way, it currently leads all publicly-scored frontier models on GPQA Diamond. That is a graduate-level science benchmark written by domain PhDs where the prior record-holder (GPT-5.4) sits at 92.0% and Claude Opus 4.6 Thinking sits at 89.6%.
How much does Gemini 3.1 Pro cost per million tokens?
$2 for input and $12 for output on prompts up to 200K tokens. Both rates double above 200K. That makes it the cheapest frontier-tier model available. Cheaper than GPT-5.4 ($2.50/$15) and substantially cheaper than Claude Opus 4.6 ($5/$25). Running the full Artificial Analysis Intelligence Index cost $892 on Gemini 3.1 Pro versus $2,486 on Claude Opus 4.6 at max reasoning.
What is Gemini 3.1 Pro's LMArena ranking in April 2026?
As of April 2026, Gemini 3.1 Pro Preview sits at #3 on the LMSYS Chatbot Arena leaderboard with an Elo near 1493. Claude Opus 4.6 Thinking holds #1 at roughly 1504, and GPT-5.4 High is near 1484. These numbers come from aggregator scrapes of the LMArena leaderboard and move day-to-day as more votes come in, so the ordering here is less stable than static-dataset benchmarks like GPQA or HLE.
What score did Gemini 3.1 Pro get on Humanity's Last Exam?
44.4% on Google's no-tools configuration per the model card, and 46.44% (±1.96) on Scale AI's leaderboard when run in Thinking High mode. That is currently #1 on the Scale AI HLE leaderboard, ahead of GPT-5.4 Pro (44.32%) and well ahead of Claude Opus 4.6 Thinking Max (34.44%). Calibration error is higher than GPT-5.4's, which means Gemini is more confidently wrong when it is wrong. Useful thing to know before you route high-stakes reasoning queries to it.
Did Gemini 3.1 Pro break FrontierMath?
No. Gemini 3 Pro broke FrontierMath in November 2025, with 38% on Tiers 1–3 and 19% on Tier 4. Gemini 3.1 Pro scored comparably. The top-line record did not move. What did move: Gemini 3.1 Pro solved a Tier 4 problem that no prior model had solved, though Epoch AI specifically noted the model's approach was "not how a human would" solve it. Underlying capability advanced even where the headline average did not.
