
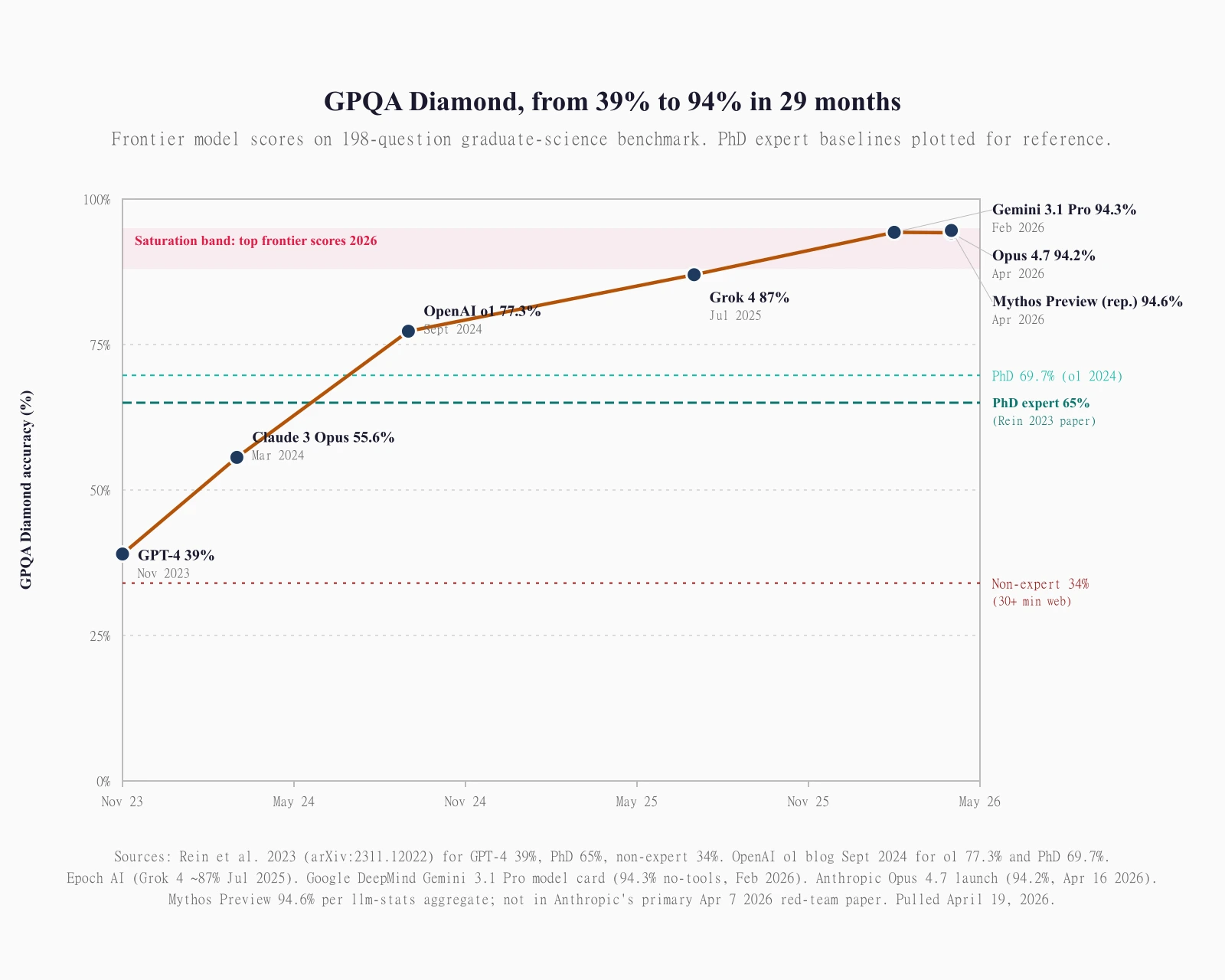
Frontier AI models now score above 94% on GPQA Diamond. The PhD experts the benchmark was built around score 65%. That gap is not a rounding error. It is the benchmark story of 2026, and it is why GPQA Diamond keeps showing up inside every serious composite index even while the people who built it are openly asking what's left.
The short answer
GPQA Diamond is a 198-question multiple-choice subset of graduate-level science drawn from physics, chemistry, and biology. It is the hardest slice of the 448-question GPQA Main set, filtered to questions where both PhD expert annotators got the answer right and at most one of three non-experts with web access did. Domain-expert humans score roughly 65% on GPQA overall per the original 2023 paper, 69.7% in OpenAI's 2024 re-benchmark. As of April 2026, Artificial Analysis publishes Gemini 3.1 Pro Preview at 94.1% and GPT-5.4 (xhigh) at 92.0% on their public GPQA Diamond leaderboard. Anthropic's official Claude Opus 4.7 launch lists 94.2%. Google DeepMind's own Gemini 3.1 Pro model card publishes 94.3%. Claude Mythos Preview's widely-cited 94.6% does not appear in Anthropic's primary red-team paper; it is secondary reporting, not a published lab number. No single leaderboard is canonical, and the 1-2 point differences you see between evaluators are inter-run variance, not model-capability gaps you can actually read.
| Model | GPQA Diamond score | Source | Date | Confidence |
|---|---|---|---|---|
| Claude Mythos Preview | 94.6% | llm-stats aggregate (not in Anthropic primary paper) | Apr 2026 | Reported |
| Gemini 3.1 Pro | 94.3% | Google DeepMind model card (no tools) | Feb 19 2026 | Confirmed |
| Claude Opus 4.7 | 94.2% | Anthropic launch, llm-stats recap | Apr 16 2026 | Reported (Anthropic self-reported) |
| Gemini 3.1 Pro Preview | 94.1% | Artificial Analysis own run | Apr 2026 | Confirmed |
| GPT-5.4 (xhigh) | 92.0% | Artificial Analysis own run | Apr 2026 | Confirmed |
| GPT-5.3 Codex (xhigh) | 91.5% | Artificial Analysis own run | Apr 2026 | Confirmed |
| Claude Opus 4.6 | 91.3% | Anthropic launch recap | Feb 5 2026 | Reported |
| Grok 4 | ~87% (±2%) | Epoch AI evaluation | Jul 2025 | Confirmed |
| PhD expert baseline | 65% (paper) / 69.7% (OpenAI re-bench) | Rein et al. 2023 / OpenAI o1 2024 | Nov 2023 / Sept 2024 | Confirmed |
| Non-expert baseline (30+ min web access) | 34% | Rein et al. 2023 | Nov 2023 | Confirmed |
What GPQA and the Diamond subset actually test
The underlying dataset comes from a November 2023 paper by David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman, out of NYU's Alignment Research Group with collaborators at Cohere and Anthropic. The paper lives at arXiv:2311.12022 and the full dataset ships from a passworded zip on GitHub.
The construction pipeline was deliberately adversarial to search. PhDs and PhD candidates in biology, physics, and chemistry wrote questions in their specialty. Another expert in the same field validated each question. Then a third pass of "highly skilled non-expert validators" (people with technical training but not in the specific subfield) attempted each question with over 30 minutes of unrestricted web access per question. Questions survived into the Main set only if at least one of two experts confirmed the answer was correct and at most two of three non-experts could solve it with search. That's the 448-question Main set.
Diamond is a filter on top of that. For a question to make Diamond, both experts have to agree on the answer and at most one of three non-experts with web access can solve it. That pins the subset at 198 questions where the signal-to-noise ratio is highest: questions a well-agreed expert answer exists for, and questions Google demonstrably cannot solve. Every frontier model announcement since 2024 reports Diamond, not Main, because Main carries more methodological noise.
The questions are four-way multiple choice, which sets the floor for guessing at exactly 25%. On the Main set, non-expert validators with 30 minutes of web access reached 34%. That is nine percentage points above guessing after half an hour of searching. The gap between Google-with-a-brain and chance is the benchmark's whole point. If you don't already have the expertise, retrieval does not rescue you.
The human expert baseline everybody argues about
The original paper reports the PhD expert baseline as 65%, or 74% if you remove questions where experts later admitted in retrospect that they had made clear mistakes. That's the number the benchmark was designed around.
OpenAI ran its own human baseline for the September 2024 o1 announcement and measured PhD-level experts at 69.7%. The methodology was different (different recruit pool, different subset, different time limit) and the framing was unfortunate. OpenAI's blog presented o1's 78% consensus score as exceeding "the performance of PhD human experts" at 69.7%, which got truncated in coverage to "AI is smarter than PhDs."
It isn't that simple. A human PhD answering Diamond questions in their specialty on the first try is solving hard problems cold. A frontier model in 2026 has seen published versions of every textbook topic Diamond draws from, many of the research directions the question authors work in, and any adjacent problem set that survived on the open web before 2025. Both are valid measurements of different things.
"Model scores 94 and human scores 65" is not the same sentence as "model is smarter than human." The measurement answers a narrower question: given a four-option multiple-choice version of a graduate-level science problem, can the model pick the right one? GPQA Diamond rewards the kind of compressed, retrieval-plus-reasoning task frontier models are optimized to death on. It does not measure whether a model can design the next version of the experiment.
The gap story, from 39% to 94% in 29 months
The progression is the most striking thing about GPQA Diamond. At the November 2023 launch, GPT-4's zero-shot chain-of-thought score on the benchmark was 39%, barely above chance and well below both the PhD expert baseline and the non-expert search baseline. The paper's framing was that the benchmark would hold up for years.
Claude 3 Opus in March 2024 posted roughly 55.6% (the original paper's top model number) to 59.5% with 32-sample majority voting in Anthropic's own evals. That moved the frontier from below-random-plus-chance to somewhere between non-expert search and PhD expert within four months of the paper's publication.
OpenAI's o1 in September 2024 hit 77.3% zero-shot and 78.0% consensus: the first model to cleanly beat the human PhD expert baseline by OpenAI's own re-benchmarked 69.7%. That was the moment the "reasoning model" category became a real thing.
Grok 4 in July 2025, per Epoch AI's evaluation, reached 87% (±2%). Gemini 3.1 Pro in February 2026, per Google DeepMind's model card, scores 94.3% no-tools. Claude Opus 4.7 at the April 16, 2026 launch posted 94.2%. Claude Mythos Preview's secondary-reported 94.6% (circulated via llm-stats and wandb compilations, not Anthropic's primary April 7 red-team paper) closes out the chart.
Roughly two percentage points per month of improvement across the 29-month arc, nonlinearly. The big jumps clustered around o1 (reasoning-chain training), Grok 4 (test-time compute), and Gemini 3 Pro / 3.1 Pro (multimodal scaling plus tool use). The curve flattens sharply above 90% because you run out of questions that have unambiguous single correct answers.
The April 2026 snapshot, and what it actually shows
The current-April standings read like a coin flip at the top. Mythos Preview at 94.6% (reported), Gemini 3.1 Pro at 94.3% (DeepMind model card), Opus 4.7 at 94.2% (Anthropic self-reported), Gemini 3.1 Pro Preview at 94.1% (Artificial Analysis own run). Four numbers from three models that span 0.5 percentage points.
Here is the part that should calibrate how you read those numbers. Artificial Analysis's GPQA Diamond page evaluates only 32 of the 448 models it tracks. Its current displayed top 3 (Gemini 3.1 Pro Preview 94.1%, GPT-5.4 xhigh 92.0%, GPT-5.3 Codex xhigh 91.5%) does not include a Claude Opus 4.7 individual score. Anthropic publishes Opus 4.7 at 94.2% on its own launch page. AA either hasn't run it yet or has chosen not to display it. Google's model card publishes Gemini 3.1 Pro at 94.3%; AA's own run of essentially the same model comes out at 94.1%. Neither number is wrong. They are different runs.
At 198 questions, a single question's difference is half a percentage point on the score. The distance between 94.1% and 94.6% is roughly one question. The 95% confidence interval on any single Diamond run at that sample size is wider than the gap between the top four models. I don't think the public top-of-leaderboard ordering is a real ranking at this point; it is a set of four models that are statistically indistinguishable at this benchmark. Treating it otherwise is a category error.
Every careful evaluator has started wrapping Diamond numbers in qualifications. llm-stats aggregates but flags self-reported runs. Artificial Analysis runs its own. Epoch AI publishes confidence intervals. Google, Anthropic, and OpenAI each run privately. Nobody has a canonical GPQA Diamond leaderboard because the benchmark has compressed into a range where signal-to-methodology-noise is probably no longer meaningful for ordering the top few.
What 94% actually buys you
A 94 on Diamond means the model handles the overwhelming majority of graduate-level four-way multiple-choice questions in physics, chemistry, and biology correctly, including ones a non-expert with half an hour on Wikipedia couldn't solve. Five years ago the score would have been science fiction.
What it doesn't buy you: Diamond is multiple choice with only four options. It does not evaluate whether the model could propose the experiment that produced the underlying science, spot the bug in an experimental protocol, or tell you whether its explanation of the answer is correct reasoning versus plausible-sounding post hoc. Researchers have consistently found that a model that picks the right multiple-choice option still regularly generates explanations with subtle errors. The benchmark measures pattern-completion-over-domain-expertise under a tight answer format. It does not measure open-ended scientific reasoning.
Most relevant to model selection: at 94%, the marginal signal from GPQA Diamond between leading frontier models is near zero. If you're choosing between Opus 4.7, Gemini 3.1 Pro, and GPT-5.4 for a scientific-reasoning workload, Diamond will not tell you anything actionable. Look at composite indices that decompose into agents, coding, scientific reasoning, and general-knowledge categories, then pull the specific component benchmarks where the spread is wider. On Humanity's Last Exam, the harder sibling of GPQA in AA's Scientific category, Gemini 3.1 Pro leads at 44.7% and GPT-5.4 xhigh sits at 41.6%. That gap still discriminates.
The benchmark's own creators are questioning it
In May 2025, Greg Burnham published a long deep-dive titled "GPQA Diamond: What's Left?" on Epoch AI's Substack. His framing: state-of-the-art models had clustered around 83% accuracy, and one of the benchmark creators had speculated that "there's something wrong with the other 17%." Burnham looked at the 40 hardest Diamond questions and categorized them. His overall estimate: roughly 8% invalidity across Diamond, with about 90-95% of questions still well-formed.
That matters because 8% of 198 questions is about 15 questions. If those 15 aren't solvable the way the answer key claims, then the practical ceiling for any model is about 92%, not 100%. Scores at 94+ are either models getting lucky on disputed questions, models getting those questions right because the answer key is actually correct and the critique is wrong, or some mix. The tightness of the top bracket is partly capability, partly noise at the edge of the benchmark's discriminative life.
Burnham also found organic chemistry overrepresented in the hardest questions: 70% of the 40 most-missed items despite only 36% of the overall benchmark. The shape of where models still fail is narrower than the benchmark advertises.
The deeper critique comes from lead author David Rein, who wrote in an NYU Alignment Research Group post that he expected "up to about a third of the questions" in the Extended dataset to contain mistakes. Extended is looser than Diamond, but the principle applies. Benchmarks written by humans at scale will have errors, and the useful framing isn't perfection but whether the benchmark still measures what it claims. Rein's answer is essentially yes: Diamond is still a good signal, just not a precise one at the top of the range.
What comes after GPQA Diamond
The obvious successor is Humanity's Last Exam, released January 2025 by the Center for AI Safety and Scale AI, with 2,500 expert-vetted questions across a much broader set of fields. Top models currently score in the low 40s on HLE: Gemini 3.1 Pro Preview 44.7%, GPT-5.4 xhigh 41.6%, GPT-5.3 Codex xhigh 39.9% per Artificial Analysis. That is the range where Diamond was in 2024. HLE is the new scaling curve.
CritPt is another candidate: 71 unpublished physics problems from 50+ physicists, still at 30% for even the best frontier model (GPT-5.4 Pro xhigh), base-model average 4%. CritPt discriminates where Diamond no longer can. GDPval-AA moves the framing off multiple choice entirely, using blind pairwise comparison of long-form outputs judged by GDP-sector experts and scored as Bradley-Terry ELO.
The prediction for 2027: GPQA Diamond will still appear on launch slides (no serious model launch currently omits it) but its role will have moved from primary capability signal to component weight inside a composite index. That is the direction AA v4.0 already pointed in January 2026 when it dropped MMLU-Pro and AIME 2025 (both saturated) and kept Diamond at 6.25% of the total composite, well under the 12.5% weight on HLE. Diamond is already treated as a component, not a standalone.
How to actually use Diamond when shopping models
A practical reading for model selection:
- Below 60%: not a frontier model for science reasoning. Excludes most open-weight models under about 100B parameters.
- 80-90%: strong modern frontier. Bracket currently includes Grok 4, Claude Opus 4.6, and several open-weights like GLM-5.1.
- 94+: top bracket of closed-frontier capability. The exact position within that bracket (which lab reports 94.1 vs 94.3 vs 94.6) is not meaningful for workload decisions.
Do not let a single-point GPQA Diamond headline drive model selection. A one-question difference on a 198-question benchmark is not a capability gap. The labs that know this best have already moved to component decomposition inside composite scores.
For the broader April 2026 frontier model context, see the comparison of Claude Mythos Preview, GPT-5.4-Cyber, and the Anthropic-OpenAI cybersecurity split, the Gemini 3.1 Pro benchmark breakdown covering GPQA, HLE, LMSys, and FrontierMath, and the decomposed Artificial Analysis Intelligence Index that uses GPQA Diamond as a 6.25% weighted component.
Frequently asked questions
What does GPQA stand for?
GPQA stands for Graduate-level Google-Proof Q&A. The "Google-Proof" part is the key design claim: the questions were filtered so that highly skilled non-experts with 30+ minutes of unrestricted web access still only reached 34% accuracy on the Main 448-question set. If you can solve the questions with Google, they're not in the benchmark.
How is GPQA Diamond different from GPQA Main?
GPQA Diamond is a 198-question subset of the 448-question Main set. To make Diamond, a question needs both expert annotators to agree on the answer and at most one of three non-experts with web access to solve it, a stricter filter than Main (which requires only one of two experts to agree and at most two of three non-experts to solve). Diamond is used for frontier model evaluation because its questions have the highest signal-to-noise ratio. Main is noisier and has more questions with ambiguous answer keys.
What is the human PhD expert baseline on GPQA Diamond?
The original 2023 paper by Rein et al. reports 65% PhD expert accuracy, or 74% when discounting clear mistakes experts identified in retrospect. OpenAI's September 2024 o1 announcement re-benchmarked with its own PhD-level expert pool and measured 69.7%. Both numbers are valid. The gap reflects different recruit pools and methodology, not a change in human capability.
Which model has the highest GPQA Diamond score in April 2026?
As of April 2026, Claude Mythos Preview is the most widely reported highest scorer at 94.6%, though that number appears only in secondary aggregator coverage (llm-stats, wandb) and not in Anthropic's primary red-team paper. Gemini 3.1 Pro's official Google DeepMind model card lists 94.3%. Claude Opus 4.7's April 16, 2026 Anthropic launch lists 94.2%. On Artificial Analysis's own independent evaluation, Gemini 3.1 Pro Preview leads at 94.1%. The top four scores span 0.5 percentage points, roughly one question on a 198-question test, so treating this as a real ranking is a mistake. The models are statistically indistinguishable at this benchmark.
Is GPQA Diamond still a useful benchmark in 2026?
Partially. GPQA Diamond remains useful as a capability floor: any model that scores under 80% is not a top-tier frontier model for scientific reasoning. But the discriminative power at the top of the range has collapsed. With top models clustered within 1-2 percentage points of each other, the benchmark can no longer cleanly rank the frontier. That's why Artificial Analysis's Intelligence Index v4.0 weights Diamond at only 6.25% and pairs it with Humanity's Last Exam (12.5% weight) and CritPt (6.25% weight), where scores are still in the 25-45% range and the spread between models is actually readable.
Why does Claude Mythos Preview not appear on Artificial Analysis's GPQA Diamond leaderboard?
Claude Mythos Preview is a gated research preview, announced April 7, 2026, available only through Project Glasswing partnerships for defensive cybersecurity use cases. Artificial Analysis only evaluates publicly accessible models. Mythos's 94.6% GPQA Diamond score that shows up in aggregator coverage is secondary reporting, likely traced back to Anthropic's preview partner materials or the model's system card, not a published number in Anthropic's primary April 7 red-team paper at red.anthropic.com. That paper focuses on cybersecurity capabilities and notes that Mythos "mostly saturates" standard benchmarks without reproducing specific figures.
What benchmark comes after GPQA Diamond?
Humanity's Last Exam is the most direct successor, a broader, harder benchmark with 2,500 expert-vetted questions across many more fields. Top models currently sit in the low 40s on HLE, which is where Diamond was in 2024. CritPt (71 unpublished physics problems, top frontier model at 30%) and GDPval-AA (blind pairwise ELO on long-form outputs) fill the space where Diamond no longer discriminates. Expect GPQA Diamond to persist on launch slides through 2027 as a component signal, but its standalone days are ending.
