
The LMSys Chatbot Arena is the most-referenced and least-understood ranking in AI. It is not a benchmark. It is a human preference poll, counted with a Bradley-Terry model that the public UI labels as “Elo.” As of April 19, 2026, Anthropic‘s Claude Opus 4.7 Thinking sits at the top of the live text leaderboard at roughly 1505 Elo, with Anthropic models holding four of the top five slots inside a 20-point cluster that, statistically, is a coin flip.
Two structural things sit on top of that number and deserve to sit on top of any analysis. First, lmarena.ai no longer serves a leaderboard. It 301-redirects to arena.ai, and neither domain ships a machine-readable API. Every published Arena ranking is a human-eyeball reading of a rendered web page, frozen the minute it was pulled. Second, Arena Elo updates continuously as new votes arrive, so the snapshot below reflects a fetch on April 17-19, 2026 and will have drifted by the time you finish this article.
| Rank | Model | Provider | Elo |
|---|---|---|---|
| 1 | Claude Opus 4.7 Thinking | Anthropic | 1505 |
| 2 | Claude Opus 4.6 Thinking | Anthropic | 1503 |
| 3 | Claude Opus 4.7 | Anthropic | 1498 |
| 4 | Claude Opus 4.6 | Anthropic | 1497 |
| 5 | muse-spark | Meta | 1496 |
| 6 | Gemini 3.1 Pro Preview | 1492 | |
| 7 | Gemini 3 Pro | 1486 | |
| 8 | Grok 4.20 Beta1 | xAI | 1485 |
| 9 | GPT-5.4 High | OpenAI | 1482 |
| 10 | Claude Sonnet 4.6 Thinking | Anthropic | 1467 |
Confidence intervals on individual entries range from approximately plus-or-minus 5 to plus-or-minus 11 Elo. Claude Mythos Preview is absent from Arena for the same reason it is absent from the Artificial Analysis Intelligence Index: Anthropic keeps it inside Project Glasswing partner access, not on public preference rails. All Arena Elos marked “reported” per the note on machine-access opacity.
What LMSys Arena actually measures, and how
The Arena came out of a UC Berkeley consortium. Chiang, Zheng, Sheng, Angelopoulos, Li, Li, Zhang, Zhu, Jordan, Gonzalez, and Stoica submitted the paper to arXiv on March 7, 2024, and it landed at ICML 2024. The platform itself had been running since late April 2023. As of paper submission, they had collected roughly 240,000 votes from over 90,000 users. The live site now reports more than 5.8 million votes across 635 tracked models.
The mechanism is simple. A user types a prompt. Two anonymized models answer side-by-side. The user picks the better response, or ties, or says both were bad. The model identities reveal only after the vote. Aggregate those votes and you get a preference ranking.
The scoring, however, is not really Elo. In December 2023, LMSys switched from rolling Elo updates to a Bradley-Terry model fitted to the full vote history, with maximum-likelihood estimation and bootstrap confidence intervals. The public-facing number is still called “Elo” because users expect that label, but under the hood it is a BT coefficient rescaled to look familiar. The switch makes rankings more stable and the ordering invariant to the sequence votes arrive in.
On August 28, 2024, the team shipped “style control,” a regression add-on that separates the effect of presentation (answer length, markdown headers, bold, lists) from substance. Length turned out to be the dominant confound, with a coefficient in the 0.249 to 0.267 range across their fits. A model that writes long, well-formatted answers picks up Elo it did not earn on content. The style-control toggle on the Overall and Hard Prompts boards strips that away, and rankings shift visibly when you flip it.
The other thing worth knowing is that there is no single Arena leaderboard. There is an Overall board, and then category boards for Hard Prompts, Coding, Math, Creative Writing, Multi-Turn, Longer Queries, and several languages. The orderings diverge, sometimes wildly. On the coding board as of the April 2026 scrape, Anthropic occupies all five top slots: Opus 4.6 at 1549, Opus 4.6 Thinking at 1545, Sonnet 4.6 at 1523, Claude 4.5 Thinking at 1491, Opus 4.5 at 1465. The Overall board looks roughly similar at the top but the margins shift.
The April 2026 snapshot at the top
The headline fact about the April 2026 Overall text leaderboard is how tight the top is. Rank 1 (Opus 4.7 Thinking, 1505) and rank 6 (Gemini 3.1 Pro Preview, 1492) are 13 Elo apart. Under Bradley-Terry, that translates to roughly a 52 percent expected win rate for the top model in a head-to-head. That is one point above random.
Anthropic owns the top cluster. Opus 4.7 Thinking, Opus 4.6 Thinking, Opus 4.7 plain, and Opus 4.6 plain take ranks one through four. Meta’s “muse-spark” sits at five at 1496. The model label is opaque, and Meta has not publicly confirmed whether muse-spark is a Llama-5 variant, a research release, or one of the pre-release test variants flagged in the 2025 Leaderboard Illusion paper. The entry is simply there.
Google’s Gemini 3.1 Pro Preview sits at six, Gemini 3 Pro at seven. xAI’s Grok 4.20 Beta1 at eight. OpenAI’s GPT-5.4 High at nine. Claude Sonnet 4.6 Thinking at ten. The entire top-ten spans about 38 Elo.
Two notes are worth adding to that snapshot. Opus 4.7 launched on April 16-17, 2026, three days before this article’s fetch. It entered the live leaderboard near the top almost immediately, which is either a ringing endorsement from early voters or a signal about how sensitive the ranking is to a small number of preference votes early in a model’s life. Probably both. And Claude Mythos Preview does not appear on the board at all, because Anthropic restricted it to Project Glasswing consortium partners only, outside the public preference rails.
Why Arena rankings diverge from benchmark rankings
This is the part of the story the leaderboard does not tell you on its own. A model can be near the Arena top and mid-table on capability composites, or vice versa. Plot Arena Elo on one axis and a capability composite like the Artificial Analysis Intelligence Index on the other, and the cluster does not sit on a diagonal. It sprays.
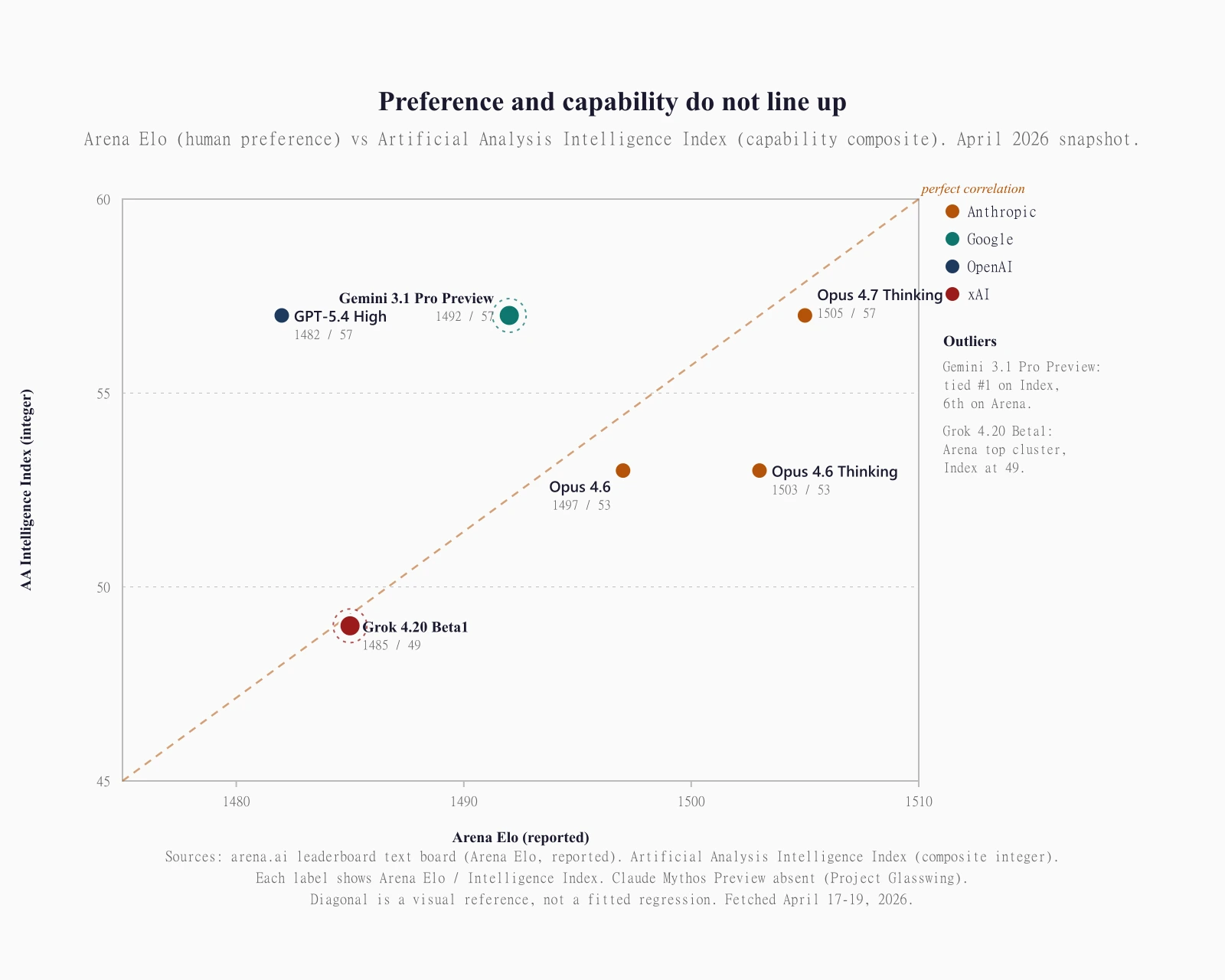
Two outliers carry the thesis. Gemini 3.1 Pro Preview ties for first on the Intelligence Index composite at 57, but sits sixth on Arena at 1492. Users voting side-by-side do not reward it the way capability evals do. Grok 4.20 Beta1 goes the other direction. It clocks Arena Elo 1485, tucked inside the top-ten cluster, while its Intelligence Index sits at 49, well below the three-way tie at 57. Voters like it more than the capability composite does.
There are real reasons for the split. Arena prompts are drawn from whatever casual and professional users happen to type, so the distribution skews toward open-ended, conversational, “vibe-check” tasks. The Intelligence Index weights GDPval-AA at 16.7 percent, Terminal-Bench Hard at 16.7 percent, AA-Omniscience at 12.5 percent, HLE at 12.5 percent. Those are expert-vetted, hard, agentic or scientific. A model that writes warm, grammatically pristine conversational English and refuses gracefully will collect Arena votes it will not collect on Terminal-Bench Hard. A model tuned for agentic task completion in a shell sandbox will win capability weights without necessarily charming a user in a chat window.
Gemini’s profile looks capability-heavy and preference-light. Grok’s looks preference-heavy and capability-light. Anthropic’s Opus variants cluster near the top on both axes, which is the closest thing to a diagonal-aligned lab in the current frontier. That convergence is unusual. It is easier to be good on one scoring system than both at once.
GDPval-AA Elo, the newer pairwise measure
A second Elo-style leaderboard is worth knowing about, because it shows how different a preference number looks when the voters are different. Artificial Analysis’s GDPval-AA uses the same Bradley-Terry fitted-model machinery as Chatbot Arena. The judging difference is what it evaluates.
GDPval-AA runs 1,320 real-world, economically-valuable tasks spanning 44 occupations across nine major U.S. GDP-contributing industries. Models get shell access and web browsing via AA’s Stirrup harness. Blind pairwise comparisons between model outputs and reference outputs feed the Bradley-Terry fit. Bootstrap confidence intervals, anchor score set so GPT-5.1 Non-Reasoning equals exactly 1,000 Elo.
As of the April 19, 2026 fetch, the top of GDPval-AA reads: Claude Opus 4.7 (Adaptive Reasoning Max Effort) at 1753. Claude Sonnet 4.6 (Adaptive Reasoning Max Effort) at 1675. GPT-5.4 xhigh at 1674. Claude Opus 4.6 (Adaptive Reasoning Max Effort) at 1619. Opus 4.7 has a 79-Elo lead on second place. Under Bradley-Terry, a 79-Elo gap is a 61 percent expected win rate.
The thing worth noticing is Gemini 3.1 Pro Preview. It ties for first on the Intelligence Index composite at 57. On GDPval-AA it sits at 1314, a 439-Elo gap behind Opus 4.7, which maps to roughly a 92 percent expected win rate for the Anthropic model in a head-to-head agentic task. Same lab’s model tied for first on a capability composite; nearly saturated against on a pairwise agentic Elo. The same thing happens in the reverse direction when you move from GDPval-AA back to Chatbot Arena: Opus 4.7 at Arena 1505 holds a roughly coin-flip gap over Gemini at 1492, not the 92 percent that GDPval-AA implies. The two preference systems disagree because their task distributions disagree.
Treat any headline number skeptically until you know which voter pool produced it.
How to read Arena Elo honestly
A few rules of thumb that hold up across snapshots.
Twenty Elo is coin flip. If the top six models span 20 points, the rank order inside that cluster is a statement about sample size and user distribution, not model quality. Do not let a three-place swing from one week to the next change your procurement decision.
Toggle style control for anything real. If you are evaluating a model for writing tasks where length and format discipline matter, the style-controlled rankings are the honest number. If you want a conversational “what do users like” read, leave it off.
Check the category boards. A model that leads Overall and trails Coding by 40 Elo is telling you something. A lab that owns the Coding top-five and places sixth on Math is telling you something else. The Overall board compresses category signal into a single mean, and the mean hides most of the interesting structure.
Anchor to capability composites before you anchor to Arena rank. The Arena answers “which model do users prefer when typing whatever they felt like typing.” GPQA Diamond answers whether a model can beat a PhD on graduate science, which is a different question. GDPval-AA answers whether a model can do a day of work. Decide what you are optimizing for, then pick the ranking that measures it.
Watch the confidence intervals. The live leaderboard shows plus-or-minus margins for each entry, often plus-or-minus 5 to plus-or-minus 11 Elo. Many outlets that re-publish Arena rankings strip those intervals out. The intervals are the honest part of the number.
Treat the leaderboard date as part of the claim. An Arena rank from February is not the same number as an Arena rank from April. Arena votes arrive continuously and the BT fit updates accordingly.
The critique: machine access and selective disclosure
The first layer of critique is the one above: the primary source is fetch-hostile. When the canonical URL for the most-cited AI ranking 301-redirects to a rebrand with no public machine-readable leaderboard, the “leaderboard” is effectively what one person with a browser says it is at a given moment. That is not a conspiracy; it is a technical choice. But it is a technical choice that makes the ranking harder to audit and easier to misquote.
The second layer is academic. On April 29, 2025, a thirteen-author team led by Shivalika Singh at Cohere Labs, with co-authors from AI2, Princeton, Stanford, Waterloo, and UW, and Sara Hooker as senior author, posted “The Leaderboard Illusion” to arXiv. The paper runs sixty-eight pages. Its headline findings: Meta tested twenty-seven private Llama-4 variants on the Arena in the runup to the Llama-4 release and disclosed only the best one. Google received an estimated 19.2 percent of all Arena votes. OpenAI received 20.4 percent. Eighty-three open-weight models combined received 29.7 percent. Under the paper’s experimental setup, access to Arena data yielded up to 112 percent relative performance gains on the Arena distribution itself. The paper calls this “selective disclosure” and “sampling disparity.”
LMArena responded on its official blog. The response argues the paper undercounts open-weight models (claiming 40.9 percent share vs the paper’s 8.8 percent), that pre-release testing boosts performance by only about 11 Elo after 50 tests and 3,000 votes rather than the paper’s larger numbers, and that “any model provider can submit as many public and private variants as they would like, as long as they have capacity for it.” They also note that their policy on evaluating unreleased models has been publicly posted since March 1, 2024.
Simon Willison called LMArena’s response “disappointing” because it sidesteps the core complaint. Vendors can submit many variants, see which one performs best, and publish only that one. Even if every number in the Cohere paper were off by half, the selective-disclosure dynamic is real and the response does not refute it. The honest fix, per Willison, is a transparency footnote showing how many variants each vendor tested.
Ray Perrault, co-director of the Stanford AI Index 2026, makes the broader point that applies to every AI ranking, Arena included. “Knowing that a benchmark for legal reasoning has 75 percent accuracy tells us little about how well it would fit in a law practice’s activities.” Arena’s 1505 Elo tells you Opus 4.7 Thinking is marginally preferred by Arena voters over its next closest peer. It does not tell you whether the model will hold up on your actual workload. No leaderboard can.
Frequently asked questions
What is the LMSys Arena Elo rating?
It is a ranking score produced from pairwise human preference votes between two anonymized model responses to the same prompt. The “Elo” label is a UI convention. Since December 2023 the underlying math is a Bradley-Terry model fitted via maximum-likelihood estimation with bootstrap confidence intervals. LMSys Arena launched in April 2023 out of a UC Berkeley consortium led by Wei-Lin Chiang, Lianmin Zheng, and Ion Stoica. The paper appeared at ICML 2024.
Which model leads LMSys Arena in April 2026?
On the live arena.ai text leaderboard as of April 17-19, 2026, Claude Opus 4.7 Thinking leads at roughly 1505 Elo, followed by Claude Opus 4.6 Thinking at 1503, Claude Opus 4.7 at 1498, Claude Opus 4.6 at 1497, and Meta’s muse-spark at 1496. Anthropic holds four of the top five slots. All numbers marked “reported” because Arena Elo updates continuously and lmarena.ai no longer exposes a machine-readable leaderboard API.
Why does the leaderboard rank differ from capability benchmarks?
Arena prompts are drawn from whatever users happen to type, which skews toward conversational and open-ended tasks. Capability composites like the Artificial Analysis Intelligence Index weight expert-vetted evaluations such as GDPval-AA, Terminal-Bench Hard, HLE, and GPQA Diamond. The two distributions reward different strengths. Gemini 3.1 Pro Preview ties for first on the Intelligence Index at 57 but sits sixth on Arena. Grok 4.20 Beta1 sits in the Arena top ten but posts an Intelligence Index of 49.
What is the Leaderboard Illusion paper?
A sixty-eight-page academic critique posted to arXiv on April 29, 2025 by thirteen authors led by Shivalika Singh at Cohere Labs, with Sara Hooker as senior author and collaborators from AI2, Princeton, Stanford, Waterloo, and UW. The paper documents twenty-seven private Meta Llama-4 variants tested on Arena before release with only the best one disclosed, along with an estimated 19.2 percent of votes going to Google and 20.4 percent to OpenAI versus 29.7 percent to 83 open-weight models combined. LMArena responded disputing several figures; Simon Willison called the response “disappointing” for sidestepping the selective-disclosure complaint.
What is style control in the Arena?
A regression toggle launched on August 28, 2024 that separates the effect of presentation (answer length, markdown headers, bold, lists) from substantive content in the Bradley-Terry fit. Length was the dominant confound, with a coefficient in the 0.249 to 0.267 range. Style-controlled rankings differ from the default Overall ranking, sometimes by several places.
What is GDPval-AA and how is it different from Chatbot Arena?
GDPval-AA is Artificial Analysis’s own pairwise leaderboard, fitted with the same Bradley-Terry machinery as Arena but judged on 1,320 real-world, economically-valuable tasks spanning 44 occupations across nine major U.S. GDP-contributing industries. Models get shell access and web browsing via AA’s Stirrup harness. As of April 19, 2026, Claude Opus 4.7 leads at 1753 Elo, followed by Claude Sonnet 4.6 at 1675, GPT-5.4 xhigh at 1674, and Claude Opus 4.6 at 1619. Gemini 3.1 Pro Preview sits at 1314, a 439-Elo gap behind Opus 4.7.
Is LMSys Arena Elo reliable for model selection?
It is a useful signal, not a canonical ranking. A 20-Elo spread is roughly a coin flip, so fine-grained rank differences in the top cluster do not carry procurement weight. Toggle style control, check the category boards that match your actual workload, and treat Arena Elo as one of at least two or three rankings you cross-reference. The Intelligence Index, GDPval-AA, and task-specific benchmarks like Terminal-Bench Hard or SWE-bench Verified answer different questions. Pick the ranking that measures what you are optimizing for.
