
Two years ago, the case for open-source AI was idealism: closed labs would always hold the frontier, but the world should have alternatives anyway. In April 2026 it is not idealism. On several axes that matter for production deployment, open-weight models from Chinese labs now match or beat the proprietary frontier. On others, including the canonical Chatbot Arena Elo, Stanford's 2026 AI Index reports the gap actually widened. The honest story is messier than a clean "gap closed" headline, and sharper for it.
The 60-second answer
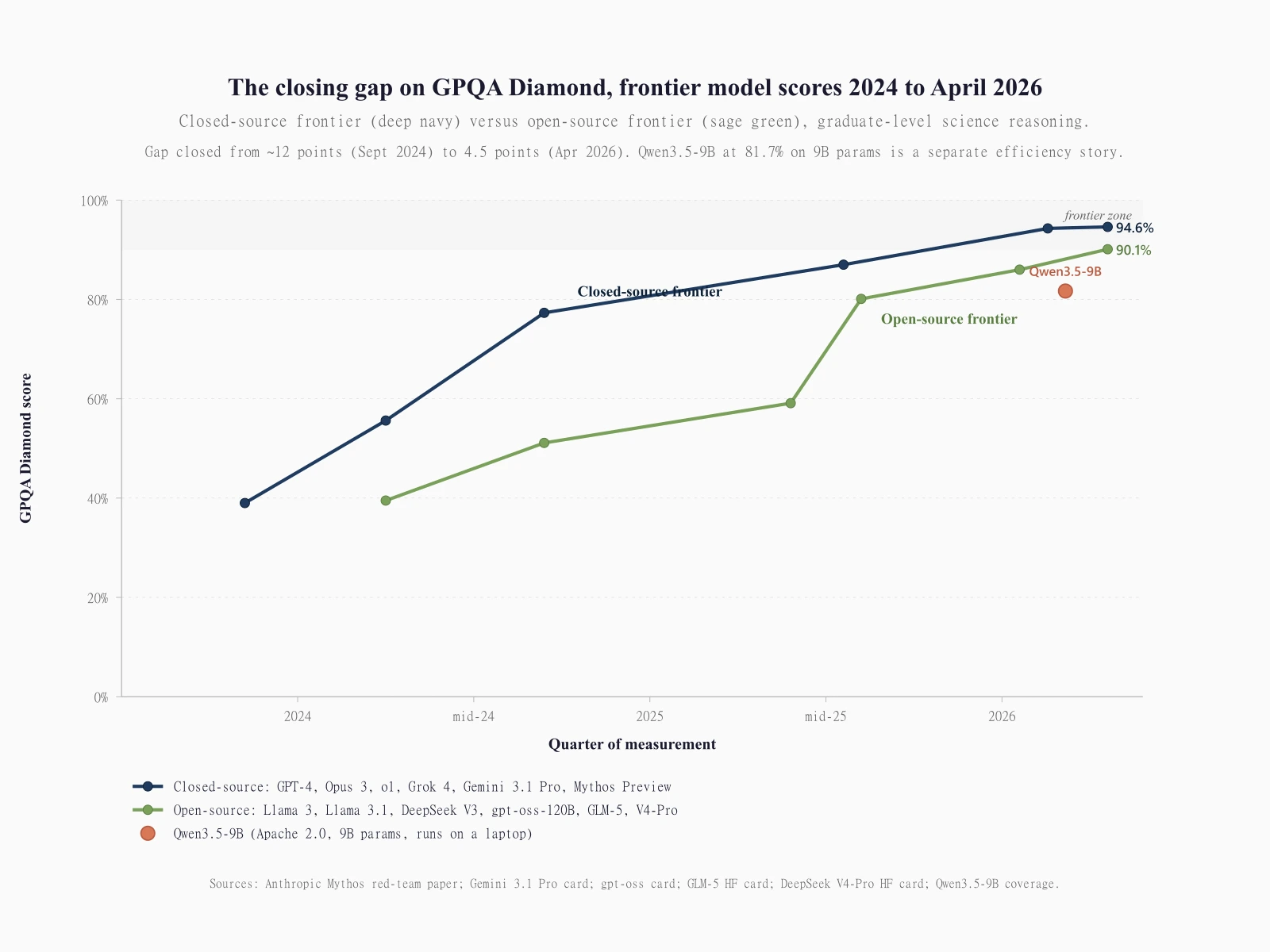
GLM-5.1 from Z.ai took #1 on the SWE-Bench Pro leaderboard on April 7, 2026 with a 58.4 score, ahead of GPT-5.4 at 57.7 and Claude Opus 4.6 at 57.3. Kimi K2.6, released April 20, scored 58.6 on the same benchmark. DeepSeek V4-Pro, three days old at this writing, hits 90.1% on GPQA Diamond and ships at $1.74 input / $3.48 output per million tokens, roughly one-sixth the cost of Claude Opus 4.7. Llama 4 Scout shipped a 10 million token context window, ten times deeper than any closed-source frontier model. Alibaba's 9-billion-parameter Qwen3.5-9B beat OpenAI's gpt-oss-120B on GPQA Diamond by 1.6 points, despite using roughly thirteen times fewer parameters.
That is the optimistic frame. The pessimistic frame: Stanford's 2026 AI Index reports the closed-source/open-source Chatbot Arena Elo gap widened to 3.3% from 0.5% in August 2024, with Claude Opus 4.6 at 1503 leading the strongest open model GLM-5 at 1454 by 49 Elo points. On the Artificial Analysis Intelligence Index v4.0, the closed cluster sits at 57 (Opus 4.7, Gemini 3.1 Pro, GPT-5.4 xhigh) versus the top open model GLM-5.1 at 51, a six-point gap on a composite metric. On SWE-bench Verified, Claude Opus 4.7 at 87.6% leads GLM-5 at 77.8% by 9.8 points, a gap that reopened when Anthropic shipped Opus 4.7 on April 16.
The "gap closed" claim survives if you read it carefully. On cost, on parameter efficiency, on long-horizon coding tasks measured by SWE-Bench Pro, on context depth, and on inference economics, open-weight models are now competitive enough that closed-source dominance is no longer the default assumption for enterprise deployment. On the absolute top of the leaderboard, closed-source still leads.
| Benchmark | Closed-source leader | Open-source leader | Gap | Verdict |
|---|---|---|---|---|
| GPQA Diamond | Mythos Preview 94.6% (reported) | DeepSeek V4-Pro Max 90.1% | 4.5 pp | Closed leads |
| SWE-bench Verified | Claude Opus 4.7 87.6% | GLM-5 77.8%, V4-Pro 80.6% | 7.0 to 9.8 pp | Closed leads |
| SWE-Bench Pro | GPT-5.4 (xhigh) 57.7 | Kimi K2.6 58.6, GLM-5.1 58.4 | Open leads by 0.7-0.9 pp | Open leads |
| HLE (Humanity’s Last Exam) | Mythos Preview 64.7% w/ tools | GLM-5 50.4% w/ tools | 14.3 pp | Closed leads |
| Context window | 1 million tokens | Llama 4 Scout 10 million | Open leads by 9 million | Open leads |
| Cost per 1M output tokens | Opus 4.7 $25 / GPT-5.5 $30 | V4-Flash $0.28 / V4-Pro $3.48 | 7-90x cheaper open | Open leads |
| Intelligence Index v4.0 | Opus 4.7 / Gemini 3.1 / GPT-5.4 xhigh tied at 57 | GLM-5.1 Reasoning 51 | 6 points | Closed leads |
| Chatbot Arena Elo | Opus 4.6 ~1503 | GLM-5 ~1454 | 49 Elo / 3.3% (Stanford 2026) | Closed leads (gap widened) |
The Chinese open-source wave is the real story
The U.S. labs still own the top of every closed-source leaderboard. The shift is who is right behind them. Three Chinese labs (Z.ai, formerly Zhipu, plus Moonshot and DeepSeek) pushed weights public on April 7, April 20, and April 24 respectively. All three under MIT or modified-MIT licenses. All three on Hugging Face for direct download. The three releases together cover the full hardware envelope from a single H100 to a 256-GPU rack.
GLM-5 dropped on February 17 from Z.ai. 744B total parameters with 40B active per token in a Mixture-of-Experts design. MIT license. 28.5 trillion training tokens. The model card lists 86.0% on GPQA Diamond, 50.4% on Humanity's Last Exam with tools, and 77.8% on SWE-bench Verified. The 77.8% on Verified is exactly three points behind Claude Opus 4.6's 80.8% on the same benchmark, the framing Z.ai built its launch deck around. The Opus 4.7 release on April 16 widened that gap to 9.8 points, but Z.ai's framing was correct on the day they shipped.
GLM-5.1 followed on April 7. 754B MoE, MIT license, 58.4 on SWE-Bench Pro, taking #1 on that variant of the SWE-bench family. SWE-Bench Pro is a contamination-controlled SWE-bench variant with longer-horizon engineering tasks. Closed-source leaders trail GLM-5.1 on this measure: GPT-5.4 (xhigh) at 57.7, Claude Opus 4.6 (max effort) at 53.4, Gemini 3.1 Pro (thinking high) at 54.2. Kimi K2.6 from Moonshot, released April 20, edged GLM-5.1 by 0.2 points at 58.6. Both open-weight models lead the closed-source field on this specific benchmark.
DeepSeek V4 dropped April 24, three days before this article. Two variants. V4-Pro: 1.6 trillion total parameters, 49 billion active per token, 1 million token context, MIT license, trained on 32+ trillion tokens. V4-Flash: 284B total / 13B active. The V4-Pro Max numbers from DeepSeek's official model card are striking. 90.1% on GPQA Diamond, 80.6% on SWE-bench Verified, 37.7% on Humanity's Last Exam, 93.5% on LiveCodeBench, Codeforces rating 3206. The GPQA Diamond number puts V4-Pro about 4 points behind the closed-source 94% cluster. The pricing makes that gap look very different in a TCO comparison.
The Qwen3.5-9B story sits separately. Released March 2 under Apache 2.0, the 9-billion-parameter model scored 81.7% on GPQA Diamond, beating OpenAI's gpt-oss-120B at 80.1%. That is a 9B model running on a laptop scoring above a 120B model running on a single 80GB GPU, on a graduate-level science reasoning benchmark. The story is not that Qwen3.5-9B beats GPT-5.5 (it does not). The story is that the floor of "models that can clear 80% on GPQA Diamond" now includes hardware most developers can run locally.
Where open-source actually wins
Cost is not close. DeepSeek V4-Pro costs $1.74 per million input tokens (cache miss) and $3.48 per million output tokens. With cached input the rate drops to $0.145. V4-Flash is $0.14 input and $0.28 output. By contrast, Claude Opus 4.7 is $5/$25, GPT-5.5 is $5/$30, and gpt-5.5-pro lands at $30/$180. Output token cost ratios run roughly 7x cheaper for V4-Pro vs Opus 4.7, and over 600x cheaper for V4-Flash vs gpt-5.5-pro. At enterprise volume with output-heavy workloads (code generation, agent runs, long-form synthesis), those ratios decide the budget.
Context depth is not close either. Llama 4 Scout shipped April 5 with a 10 million token context window. The closest closed-source is Gemini 3.1 Pro at 1M, and Anthropic's Mythos Preview also at 1M per the AWS Bedrock model card. Llama 4 Scout sits one order of magnitude deeper. The use cases are specific (multi-document summarization, full-codebase reasoning, multi-meeting transcript synthesis), and for those workloads no closed-source frontier model competes.
Parameter efficiency at the lower tier is uncontested. Qwen3.5-9B beating gpt-oss-120B on GPQA Diamond is the clean version of a broader pattern: small open models punch above their parameter weight, particularly on contamination-resistant academic benchmarks. The trend matters because deployment economics depend on parameter count more than headline scores. A model that runs on a laptop and clears 80% on graduate science is a different commercial proposition from a model that runs on a rack and clears 94%.
License terms are open. MIT (GLM-5, DeepSeek V4), Apache 2.0 (Qwen3.5-9B, gpt-oss-120B), modified MIT (Kimi K2 Thinking and K2.6). Llama 4 uses Meta's Community License: commercial use allowed, but not strictly OSI-compliant. For most enterprises with internal counsel, the open licenses pass review. The proprietary models do not, beyond standard API access.
Where closed-source still wins
On the absolute top of the public benchmark leaderboards, the closed cluster still leads. On GPQA Diamond, Mythos Preview is widely reported at 94.6%, with Gemini 3.1 Pro at 94.3%, Claude Opus 4.7 at 94.2%, and open-source leader DeepSeek V4-Pro at 90.1%. The 4.5-point gap is meaningful at the high end of capability evaluation. Article 07's primary-source teardown of GPQA Diamond covers the inter-evaluator variance: at the top of the cluster, 0.3 to 0.5 points of difference are within methodology noise, but a 4-point gap is real signal.
On SWE-bench Verified, the gap widened with Anthropic's Opus 4.7 release on April 16. Pre-Opus-4.7, GLM-5 at 77.8% was three points behind Opus 4.6 at 80.8%. Post-Opus-4.7, the closed-source leader sits at 87.6% on the same benchmark, a 9.8-point gap. DeepSeek V4-Pro at 80.6% closes some of that distance, but no open model has cleared 85% on SWE-bench Verified as of April 27.
Stanford's 2026 AI Index report goes further. On Chatbot Arena, closed-source models now outpace open-source by 3.3%, up from 0.5% in August 2024. Claude Opus 4.6 at 1503 Elo led GLM-5 at 1454 by 49 Elo points when Stanford's data was frozen. Read against the buzzy "open is closing the gap" narrative, Stanford's number reads as counter-evidence: on the metric most often cited in user-preference comparisons, the gap widened over the past 18 months, not narrowed. The discrepancy with the SWE-Bench Pro story explains itself. Different benchmarks, different evaluation protocols, different time slices. Anyone making confident "gap closed / not closed" claims without naming the specific benchmark is reading too quickly. The four-question framework for reading benchmark scores covers exactly this kind of single-metric framing problem.
Capability advantages closed labs hold beyond raw scores: safety tuning at the level Anthropic describes for Mythos Preview ("the best-aligned model according to safety evaluations" per the Opus 4.7 announcement), multimodal maturity across vision and tool use, enterprise SLAs with 99.95%+ uptime, proprietary tooling like Claude Code and OpenAI's Codex Security, and access to restricted-deployment models like Mythos Preview through Project Glasswing for sensitive cybersecurity workloads.
The economic reality of open-source TCO
Run the math at constant utilization. An enterprise running 100 million output tokens per day on a code-generation pipeline. On Claude Opus 4.7 at $25/M output, that is $2,500 per day or $912,500 per year. On DeepSeek V4-Pro at $3.48/M, the same volume is $348 per day or $127,020 per year. The difference is $785,480 per year for a single workload, roughly 86% lower spend. On V4-Flash for the same workload, $10,220 per year, a 98.9% reduction.
The math becomes more interesting if you self-host. Llama 4 Scout fits on a single H100 GPU with Int4 quantization. A 4-GPU server at ~$15K/month inference cost (cloud AWS pricing) handles substantial throughput at zero per-token marginal cost. For internal-only deployments where data sovereignty matters more than absolute capability, the calculus has flipped: proprietary API spend is now hard to justify at scale unless the workload genuinely requires capability the open frontier does not match.
Two qualifications. First, the "intelligence per dollar" framing assumes equivalent task quality, which is not always true. If GLM-5.1 fails on 10% of complex agent runs that GPT-5.5 completes, the GLM-5.1 cost saving may be eaten by retry loops, manual cleanup, and product quality drag. Run real evals on real workloads before locking in. Second, DeepSeek's price is also subsidized to a degree the company has been transparent about. V4-Pro carries a 75% promotional discount through May 5, 2026, which means the headline $1.74/$3.48 numbers expire to a higher steady-state price. Plan for that.
Simon Willison, writing on April 24, called V4 "almost on the frontier, a fraction of the price." The DeepSeek paper itself frames V4 as trailing cutting-edge competitors by "approximately 3 to 6 months." Open-source is not at the frontier. It is close enough that the price differential makes the trade real.
The Stanford AI Index 2026 data points that matter
The Stanford report drops 30 percentage points on a single benchmark in twelve months as the headline number. Frontier models gained that much on Humanity's Last Exam between the 2025 and 2026 Index reporting windows. The 2025 Index reported OpenAI's o1 at 8.8%. Stanford's 2026 Index reports the top model at approximately 38.3%, with Gemini 3.0 Pro holding that spot during the reporting window. Frontier models have since cleared 50% with tools (GLM-5 at 50.4%, Mythos Preview at 64.7% per Anthropic's reported numbers from the article 02 fact pack), though Stanford's 2026 figure stops at 38.3% because data was frozen before later releases shipped.
The same benchmark-reading framework applies cleanly here. Humanity's Last Exam is contamination-controlled (questions held private until evaluation), unsaturated (top closed-source models with thinking modes hit 46-65% with tools, well below human-expert ceiling), and discriminative (the spread between models is large enough to read meaningful differences). The 30-point year-over-year gain is real signal, not benchmark gaming, and applies to the open-source side too. GLM-5's 50.4% with tools is consistent with the trajectory.
The Stanford report also reports China narrowed the U.S. AI performance gap to 2.7%, while spending 23x less on AI investment ($7.6B vs $109.1B in 2024). That gap-narrowing applies to U.S. vs China, a different comparison from open vs closed, though the two are increasingly correlated because the leading open-source labs are Chinese. The Stanford 2026 closed/open Elo gap widening from 0.5% to 3.3% is the awkward counter-data the open-source advocacy reads around. Read the source. Read the metric. Then decide what story actually holds.
The pragmatic framework for choosing between them
Three tests determine whether open-source clears the bar for a given workload.
Test 1: Does the workload need absolute frontier capability or is "close enough" actually enough? If you are running graduate-level science reasoning at the edge of model capability, the closed-source 94% cluster on GPQA Diamond is worth the 7-90x output cost premium. If you are running standard customer-facing chat, code completion, document summarization, agent loops with retry logic, you almost certainly do not need that capability tier. Test the workload on V4-Pro or GLM-5 first. The 86% TCO savings appear when "good enough" is enough.
Test 2: Can your data leave your infrastructure? If yes, proprietary APIs are easier to integrate and have better DevOps tooling. If no (finance, healthcare, defense, regulated public-sector), open-weight self-hosted is now the only path. The license terms (MIT, Apache 2.0) survive enterprise legal review. The proprietary models do not, except through limited regulated-deployment programs.
Test 3: Is multimodal a hard requirement? Closed-source still has a multimodal maturity edge on vision and tool use. Llama 4 Scout is natively multimodal but the polish on closed-source vision (especially Gemini 3.1 Pro and Mythos Preview's 244-page system card vision evaluations) is currently ahead. If your workload needs production-grade vision, ship on closed first and revisit in six months.
The pragmatic answer is not "go open" or "go closed." It is "use both." Use closed-source for absolute-frontier workloads, multimodal-heavy work, and capabilities you literally cannot match. Use open-source for high-volume cost-sensitive deployments, data-sovereignty workloads, and anything where 95% of capability at 7-100x lower cost is the right business answer. The April 2026 frontier model ranking covers this multi-tier deployment pattern in more depth.
What closes the gap further in the next year
Two trajectories matter for the next twelve months. First, DeepSeek's claimed 27% FLOP reduction and 10% KV cache footprint vs V3.2 suggest the next generation of efficient training will continue narrowing the inference cost gap. If V5 ships with another 30% efficiency gain, the cost ratio against closed-source becomes 12-15x cheaper, forcing the closed labs to compete on capability rather than inference quality alone. Second, the U.S. labs that ship open-weight (OpenAI's gpt-oss family, Meta's Llama 4) are competitors with Chinese open labs at this point, not benevolent contributors. The structural pressure to keep open-weight credible is real on both sides of the Pacific.
The flip side: the closed-source frontier also moved this month. Opus 4.7 added 7 points to SWE-bench Verified vs Opus 4.6. GPT-5.5 shipped April 23. Mythos Preview in restricted Glasswing access remains capability-distinct enough that Anthropic deliberately reduced Opus 4.7's cyber capabilities to keep Mythos differentiated. The gap closing is not because closed is standing still. It is because open is moving faster.
The honest framing
If a vendor pitches you "open-source is now equivalent," ask them which benchmark, on which date, against which closed-source model. Stanford's 2026 AI Index, with its 3.3% Elo gap that widened from 0.5%, is a useful corrective to over-confident "the gap is gone" narratives. So is the SWE-Bench Pro leaderboard with two open-source models at the top. Both are real. Pick the one that maps to your decision.
For most enterprises in 2026, the answer is not which side wins. It is which combination of both sides delivers the right capability at the right cost for each workload. That answer was not obvious eighteen months ago. It is the working assumption now.
Frequently asked questions
Is open-source AI as good as closed-source in 2026?
Depends on the metric. On SWE-Bench Pro, two open-source models (Kimi K2.6 at 58.6, GLM-5.1 at 58.4) lead the closed-source frontier (GPT-5.4 xhigh at 57.7, Opus 4.6 max effort at 53.4). On GPQA Diamond, the closed-source cluster (Mythos Preview 94.6%, Gemini 3.1 Pro 94.3%, Opus 4.7 94.2%) leads the top open model DeepSeek V4-Pro at 90.1% by 4-5 points. On Chatbot Arena Elo, Stanford's 2026 AI Index reports the closed-vs-open gap widened to 3.3% from 0.5% in August 2024. On cost, open-source is 7-100x cheaper. The honest answer: open-source is now competitive enough that closed-source dominance is no longer the default assumption. It is not yet at the absolute top of every leaderboard.
Which open-source model is the best in April 2026?
For pure coding workloads, Kimi K2.6 (April 20, 2026) at 58.6 SWE-Bench Pro and 80.2 SWE-bench Verified, or GLM-5.1 at 58.4 SWE-Bench Pro. For breadth and price, DeepSeek V4-Pro (April 24, 2026) at 90.1% GPQA Diamond and $1.74/$3.48 per M token pricing. For long-context document workloads, Llama 4 Scout with its 10 million token context window. For laptop-scale deployment, Qwen3.5-9B at 81.7% GPQA Diamond. There is no single "best" open model; the right choice depends on workload, hardware budget, and license requirements.
How much cheaper is open-source AI compared to GPT-5.5 or Claude Opus 4.7?
DeepSeek V4-Pro is $1.74 input / $3.48 output per million tokens. Claude Opus 4.7 is $5 / $25. GPT-5.5 is $5 / $30, with gpt-5.5-pro at $30 / $180. Output token cost ratios are roughly 7x cheaper on V4-Pro vs Opus 4.7 and over 600x cheaper on V4-Flash ($0.14/$0.28) vs gpt-5.5-pro. At 100M output tokens per day, the annualized difference between Opus 4.7 and V4-Pro is approximately $785,000.
Did Stanford's 2026 AI Index say the gap closed or widened?
Both, depending on the metric. Stanford reports frontier models gained 30 percentage points on Humanity's Last Exam in a single year (8.8% to 38.3%), which applies to both open and closed sides. Stanford also reports the closed-source vs open-source Chatbot Arena Elo gap widened to 3.3% from 0.5% in August 2024. The U.S. vs China overall AI performance gap narrowed to 2.7%. The "gap closed" framing depends on which gap you mean.
What is GLM-5.1 and why does it matter?
GLM-5.1 is an open-source 754B-parameter Mixture-of-Experts model released April 7, 2026 by Z.ai (formerly Zhipu AI), available on Hugging Face under the MIT license. It scored 58.4 on SWE-Bench Pro, taking the #1 position on that benchmark globally and beating GPT-5.4 (57.7), Claude Opus 4.6 (57.3), and Gemini 3.1 Pro (54.2). It was the first open-source model to lead the closed-source frontier on a major coding benchmark, before Kimi K2.6 nudged past it at 58.6 on April 20.
Can DeepSeek V4 actually replace GPT-5.5 or Claude Opus 4.7?
For most workloads, with caveats. V4-Pro hits 90.1% on GPQA Diamond, 80.6% on SWE-bench Verified, 37.7% on HLE, all at roughly 1/6th the per-token cost of Opus 4.7 or GPT-5.5. That makes it the right choice for high-volume cost-sensitive workloads where 90-95% of capability is enough. For absolute-frontier workloads (graduate science reasoning at the edge of capability, multimodal vision at production polish, agentic loops requiring the very best instruction-following), the closed-source cluster still leads. Test on real workloads before committing to a switch. The marketing comparisons are noisier than the production ones.
What's the catch with the DeepSeek V4 pricing?
Two catches. The headline V4-Pro pricing of $1.74/$3.48 includes a 75% promotional discount valid through May 5, 2026; the steady-state price will be higher. DeepSeek has been transparent about this. Second, "matching" closed-source on benchmarks is not the same as matching closed-source in production. Agent loops, retry behavior, instruction-following on edge cases, and multimodal handling can vary in ways benchmarks miss. Pilot the workload before signing a 12-month commitment.
Do enterprises actually use open-source AI in 2026?
Yes, increasingly. Three drivers: (a) data sovereignty for regulated workloads where data cannot leave internal infrastructure; (b) cost at high-volume deployment, where the 7-100x output cost difference compounds; (c) license compliance for legal review, since MIT and Apache 2.0 pass enterprise counsel reviews that proprietary terms do not. The pragmatic deployment pattern is increasingly hybrid: closed-source for absolute-frontier capability, open-source for high-volume and sovereignty workloads, rather than picking a single "winner." The Intelligence Index decomposition piece covers how to evaluate models against your actual workload rather than headline benchmarks.
