
Frontier AI models now score above 90% on benchmarks that their predecessors scored under 40% on two years ago. Some of those gains are real. Some are Goodhart's law wearing a lab coat.
The four-question filter, in plain numbers
A useful AI benchmark number comes with four pieces of context: what the test actually measures, what "good" looks like relative to human performance, how likely training-data contamination is, and whether the benchmark is saturated. Without those four, a score is marketing, not information.
GPQA Diamond at 94.3% sounds like superhuman science. It is 198 four-way multiple-choice questions where PhDs in the relevant subfield score 65%, and the top four frontier models in April 2026 cluster within 0.5 percentage points of each other, which is one question on a 198-item test. ARC-AGI-2 at "0%" sounds like a wall AI cannot climb. It was a wall in March 2025; thirteen months later Gemini 3.1 Pro sits at 77.1% on the same benchmark, and the wall has moved to ARC-AGI-3. SWE-bench Verified at 87.6% sounds like AI is ready to ship code on its own. It is 500 hand-validated GitHub issues from twelve mature Python repositories where most issues take an experienced engineer under an hour. The headline number is real. The story it implies is not.
This article is the four-questions framework, applied to the benchmarks that actually matter in April 2026, with the saturation timeline drawn so you can see which ones still discriminate and which ones are scoring narrative.
| Benchmark | What it actually measures | Human baseline | Contamination risk | Saturation status (April 2026) |
|---|---|---|---|---|
| GPQA Diamond | 198 graduate-level science questions, 4-way multiple choice, biology / chemistry / physics | PhD in domain: 65% (paper) / 69.7% (OpenAI re-bench). Non-expert with web access: 34%. | Moderate. Diamond questions are filtered for difficulty but the dataset shipped publicly in 2023; ~8% question-validity issues per Epoch AI’s 40-hardest review. | Saturated. Top 4 models within 0.5 pp at 94+%. Already weighted only 6.25% of the AA Intelligence Index. |
| SWE-bench Verified | 500 real GitHub issues from 12 Python repos, human-validated, agentic patch generation | Not formally measured; most issues estimated under 1 hour for experienced engineer. | High. Issues come from public repos crawled before benchmark release; ‘SWE-bench Illusion’ paper (June 2025) flagged memorization concerns. | Approaching. Mythos Preview at 93.9%, Opus 4.7 at 87.6%, GPT-5.3 Codex at 85.0%; ceiling visible but not reached. |
| Humanity’s Last Exam | 2,500 expert-vetted questions, 100+ subjects, 24% multiple choice plus 76% short-answer exact-match, multimodal | Not single-number; the benchmark is designed to require graduate-level expertise per subject. | Low by design. Private hold-out maintained against overfitting; published Nature Jan 2026. | Unsaturated. Top scores 38-46%. Is the discriminative successor to GPQA Diamond. |
| MMLU | 15,908 multiple-choice questions across 57 subjects, STEM through humanities and law | Domain-expert humans: ~89.8%. | Documented. 6.5% of questions contain errors per June 2024 review (up to 57% in Virology). MMLU-CF showed 14-16 pp drop on contamination-controlled version. | Saturated. Frontier at 88+% since mid-2024. Removed from AA Intelligence Index v4.0 in Jan 2026 with MMLU-Pro and AIME 2025. |
| ARC-AGI-2 | Abstraction-and-reasoning grid puzzles, novel patterns, pass@2 scoring across 120 semi-private + 120 private eval tasks | Panel average: 60%. At least 2 humans solve every task in under 2 attempts. | Low. Private and semi-private eval splits not exposed; new tasks cycle. | Climbing fast. Launch March 2025: frontier 0-4%. April 2026: Gemini 3.1 Pro 77.1%, GPT-5.5 reportedly 85%. ARC-AGI-3 launched as the new headroom benchmark. |
What is this test actually measuring?
This is the question the press releases hope you will skip.
GPQA Diamond is 198 four-way multiple-choice questions where PhDs wrote the question, another PhD validated the answer, and three "highly skilled non-experts" with 30 minutes of unrestricted web access still couldn't solve at least two of the three (the Diamond filter). What it measures: pattern-completion-over-domain-expertise on a tight answer format. What it does not measure: whether the model can design the experiment that produced the underlying science, spot the flaw in a research methodology, or write a correct chain-of-reasoning to support its multiple-choice pick. A model that picks the right answer with bad reasoning still scores 100% on Diamond.
SWE-bench Verified is 500 real GitHub issues with their corresponding pull requests across twelve mature Python repositories like Django, Sympy, and Flask. What it measures: whether a coding agent can navigate a real codebase, edit the right files, and produce a patch that passes the project's existing tests. What it does not measure: whether the patch is what a senior engineer would write, whether it handles edge cases the existing tests don't cover, or whether the agent's process resembles human engineering. The pass-the-tests bar is the bar; the existence of a more elegant or more correct solution is not. That is why every serious lab also reports SWE-bench Pro, which is harder, and Terminal-Bench, which evaluates shell behavior under longer task horizons.
ARC-AGI-2 is a grid-puzzle benchmark designed by François Chollet to resist the kind of pattern-completion that lets models brute-force closed-book trivia. What it measures: novel pattern generalization. What it does not measure: anything you would do at a desk job. ARC-AGI is not a measure of "is this AI useful." It is a measure of "does this AI generalize from a few examples to a novel rule." Those are different questions and they do not always correlate.
The press-release move you should be allergic to is the one where a benchmark name gets used as a synonym for a capability. "Beats PhDs at science" really means "scores above a PhD baseline on a four-option multiple choice test." "Solves real-world coding" really means "passes the existing test suite on issues filtered to under one hour of engineering effort." Both can be true. Neither is the whole sentence the headline implies.
What's the human baseline?
A benchmark score without a human baseline is a number floating in space.
GPQA Diamond's baselines are unusually clean because the original paper measured them and re-measurement happened later. Domain-PhDs score 65% per Rein et al. 2023, or 69.7% per OpenAI's o1 re-benchmark in 2024. Non-experts with 30 minutes of unrestricted web access reach 34%. So a 94% model score is not "model beats PhD by 30 points." It is "model scores above re-benchmarked PhDs on a four-option test where guessing is 25%." Same direction, less sensational.
ARC-AGI-2's human baseline is two-tier. The panel average is 60%. The 2-of-2-humans pass rate is 100%, meaning every task in the eval set is solvable by at least two of the panel within two attempts. So the gap between human and model is bigger than it looks if you compare to panel averages, and smaller than it looks if you compare to "any human can solve every task." Both numbers are fair. Pick the one your argument needs and label it.
ClockBench's baseline is 90.7% for adults reading analog clocks. That should not surprise you. It surprised every multimodal-LLM team because the top model, GPT-5.4 High, scores 50.6%. Stanford's 2026 AI Index Report uses ClockBench as the canonical example of the "jagged frontier": the same models that earned gold-medal scores at the 2025 International Mathematical Olympiad cannot reliably tell time on a clock face that a six-year-old reads in two seconds.
HLE has no clean single human number because the questions are graduate-level expert-vetted and "human baseline" was not the point. The point was to ship a benchmark that resists retrieval and was hard enough to last. Without a human baseline, you read HLE as a model-vs-model discriminator, not a model-vs-human gap. That changes how the score should land in your head.
SWE-bench Verified's human baseline is the sharpest example of why this question matters. The Princeton-OpenAI team that built Verified estimated "most issues take an experienced engineer under an hour" and explicitly note in the announcement that they expect human pass rate is below 100%. They did not publish a single-number human score. You will see press coverage that compares model scores to "human level" anyway, often picking 100% as the implicit human ceiling. That is not in the source. If your model selection depends on whether the model is "better than a human engineer," SWE-bench Verified will not answer the question. It will tell you which model is better at SWE-bench Verified.
How contaminated is the training data?
The dirtiest secret in modern benchmarking is also the one easiest to demonstrate.
MMLU-CF, Microsoft's contamination-controlled rebuild of the original MMLU benchmark, showed top frontier model accuracy dropping by 14-16 percentage points compared to the original MMLU. That is a meaningful chunk of every "we scored 88% on MMLU" claim, and it tells you that a non-trivial slice of the historical MMLU score was the model recognizing test items it had memorized at training time. A 2024-2025 lexical-contamination study found a 13.8% overall contamination rate across 513 sampled MMLU test questions, going as high as 66.7% in Philosophy.
GSM8K, the grade-school math word problems benchmark, is another clean illustration. A 2023 study removing contaminated examples from the test set produced accuracy drops of up to 13% for some models. Same model, same prompt, fewer memorized items, score falls by a meaningful margin. That is the contamination signature: the model that gets a question right reliably gets a paraphrased version of the same question wrong.
The contamination question matters most for benchmarks released years ago and then ingested by every web crawler before frontier model training. MMLU released September 2020. SWE-bench's GitHub issues are from public repositories whose discussions and patches were absolutely in the training mix. GPQA Diamond shipped its dataset publicly in 2023 with passworded zip distribution, which slows but does not stop crawling.
The benchmarks designed to resist this are the ones that publish a private hold-out. HLE keeps a private question set. ARC-AGI-2 ships 1,000 public training tasks but the live leaderboard runs on a 120-task semi-private split and a 120-task private split. AA Intelligence Index components like AA-Omniscience explicitly penalize hallucinations to make memorization-without-reasoning visible. LiveBench, introduced specifically to fix MMLU's contamination weakness, refreshes its question pool on a rolling basis from recent information sources.
The practical heuristic: a benchmark older than the model's training cutoff, with public release of its full question set, should be presumed contaminated unless the test paper proves otherwise. That is true even when the lab swears it didn't train on it.
Is the benchmark saturated?
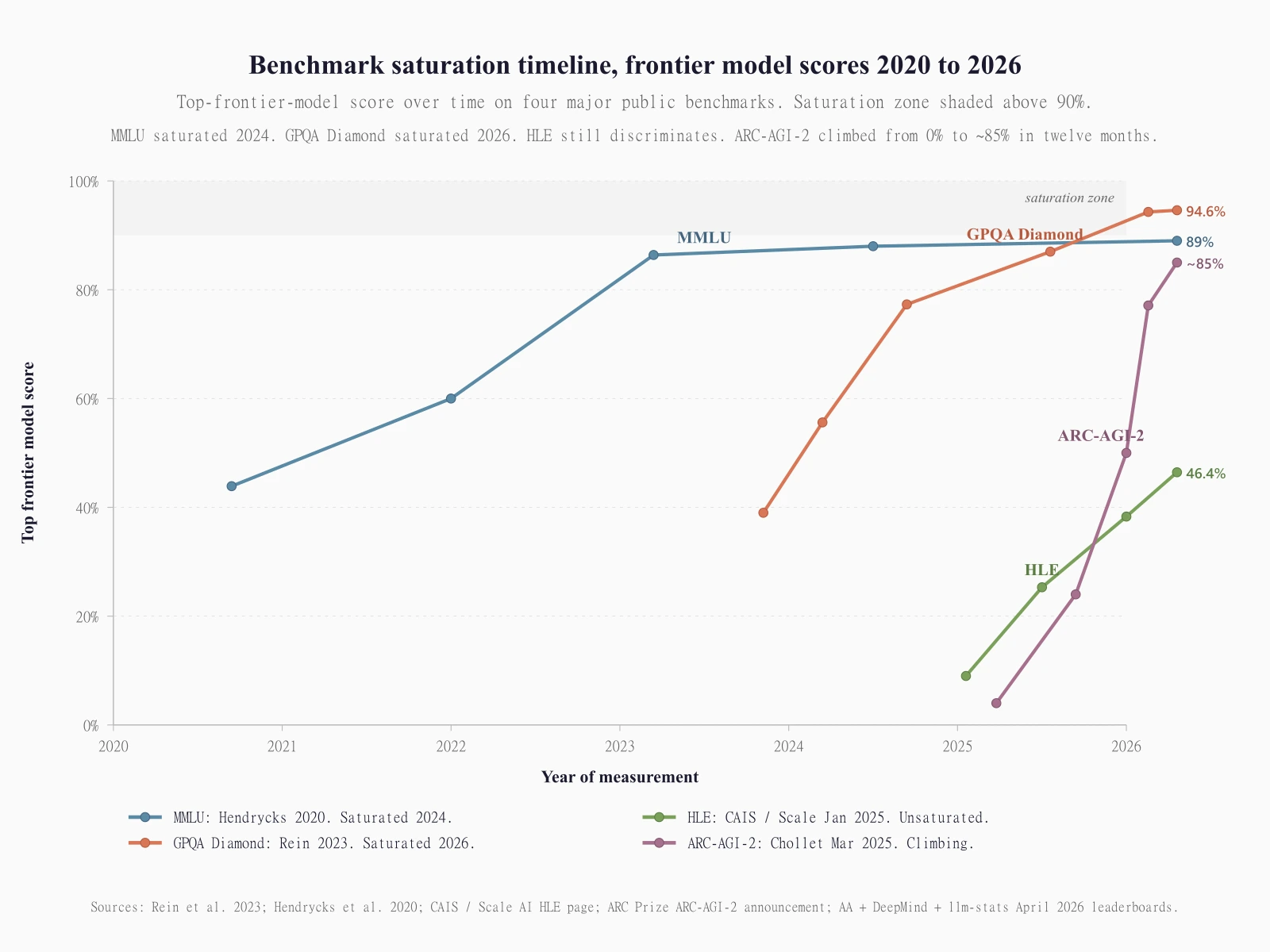
A saturated benchmark is one where the leading models cluster so tightly at the top that the benchmark no longer ranks them. GPQA Diamond is the textbook example.
In November 2023 GPT-4 scored 39% on Diamond. Twenty-nine months later Gemini 3.1 Pro scores 94.3% on Google's own model card, Claude Opus 4.7 posts 94.2% in Anthropic's launch, Claude Mythos Preview circulates in secondary coverage at 94.6%, and Artificial Analysis's independent run of Gemini 3.1 Pro Preview comes in at 94.1%. Top four scores within 0.5 percentage points. On a 198-question benchmark, that is one question. The 95% confidence interval on any single Diamond run at that sample size is wider than the gap between the top four models. I don't think this is a real ranking. It is four models that are statistically indistinguishable on Diamond, with the leaderboard order driven by run-to-run methodology variance more than capability difference. When Sanket put together the GPQA Diamond explainer from primary sources, the conclusion was the same: the benchmark has compressed past the point of discriminative use at the top.
MMLU is one step further down the saturation slope. Frontier models hit 88% by mid-2024. AA's Intelligence Index v4.0, released January 6, 2026, dropped MMLU-Pro entirely (along with AIME 2025 and LiveCodeBench) for exactly this reason: every frontier model was hitting the ceiling, so the composite score stopped moving when the underlying capability did.
ARC-AGI-2 is in the most interesting place: mid-saturation. At launch in March 2025, frontier models scored o3-preview-low 4%, o1-pro 1%, o3-mini-high 0%. The "frontier scores 0% on novel reasoning" framing came from this moment and was true. By April 2026, the same benchmark has Gemini 3.1 Pro at 77.1% per Google's own model card and GPT-5.5 reportedly at 85% on llm-stats. The original "AI cannot generalize" wall got climbed in roughly twelve months, which is why ARC Prize launched ARC-AGI-3 with its 0%-frontier scores as the new headroom benchmark. Saturation does not mean a benchmark stops being interesting. It means it stops being a current ranking and becomes a historical curve.
HLE is the one significant benchmark that is genuinely unsaturated in April 2026. The top scores sit between 38% and 46% across labs. That gap discriminates. A 6-point HLE difference between two models is real signal in a way a 0.5-point GPQA Diamond difference is not. When AA's Intelligence Index weights HLE at 12.5% and GPQA Diamond at 6.25%, that is an explicit acknowledgment that the unsaturated benchmark carries more information.
Real examples of misleading benchmark framing
This is where the four-questions framework hits the road. A few cases I have written through, with first-hand evidence on what went wrong.
The Intelligence Index decimals that don't exist. When the Gemini 3.1 Pro launch coverage hit February 19, 2026, every secondary outlet quoted decimal-precise Intelligence Index scores: "Gemini 3.1 Pro at 57.18 against Opus 4.7 at 57.17." Those decimals were nowhere on Artificial Analysis's published surface. Every public AA page, including the main leaderboard, the individual model pages, and the head-to-head comparison pages, reports the Intelligence Index as an integer. Three models tied at 57. AA's own methodology page lists a 95% confidence interval of less than ±1% on the composite. Decimal-level tied-score comparisons are doing rhetorical work that the underlying data does not support. The fact that the secondary coverage reproduces those decimals over and over makes them sound authoritative. They are not in the source.
The benchmark with no machine-readable source. Lmarena.ai 301-redirects to arena.ai. Arena.ai has no machine-readable leaderboard API. Every published Arena Elo number is a human-eyeball reading of a rendered web page, frozen the moment it was pulled. Arena votes update continuously, so the snapshot drifts within hours. When the LMSys Arena explainer needed top-10 numbers in April 2026, the only honest fetch was a manual page-load with the snapshot timestamped. Outlets that publish "Claude Opus 4.7 holds 1505 Elo" without a fetch date are publishing a number that was true for a few hours of one afternoon.
The benchmark scores that don't appear in the primary paper. Claude Mythos Preview's GPQA Diamond score of 94.6% and SWE-bench Verified score of 93.9% circulate in launch recaps from llm-stats, wandb, and aggregator coverage. They do not appear in Anthropic's primary red-team paper for Mythos Preview or in the closer parameter-and-benchmark breakdown. Anthropic's own paper uses the phrase "mostly saturates" without reproducing the standard-benchmark numbers. The 94.6% and 93.9% might be real. They might be aggregator imputations from system-card excerpts that didn't make it to public release. The honest framing is "reported, not confirmed in primary."
The 27 hidden Llama-4 variants. Cohere Labs' April 29, 2025 "Leaderboard Illusion" paper documented Meta privately testing 27 Llama-4 variants on the LMSys Arena before release and disclosing only the best one. The same paper estimated Google at 19.2% of all Arena votes, OpenAI at 20.4%, and 83 open-weight models combined at 29.7%. Access to Arena data could yield up to 112% relative performance gain on the Arena distribution itself. The structural consequence: an Arena rank is best read as a noisy signal about a vendor's best-of-N variant, not the model you actually buy.
The pattern across all four examples: the headline ranking is doing more work than the underlying data can support. Decimals are invented to break ties. Single-source numbers travel into aggregator tables and become "consensus." Confidence intervals are stripped out. Arena snapshots are reproduced without fetch dates. Secondary coverage of restricted-access models propagates numbers the primary paper never published.
The benchmarks that still discriminate in April 2026
If you are choosing between frontier models in April 2026 and you want benchmark numbers that actually carry information, the honest list is short.
HLE is the discriminator at the top. Top scores sit at Gemini 3.1 Pro Thinking High 46.44% (Scale leaderboard), GPT-5.4 Pro 44.32%, Claude Opus 4.6 Thinking Max 34.44%. A 12-point gap between top and bottom is real. The benchmark is unsaturated, contamination is bounded by the private hold-out, and the question pool is broad enough that domain narrowness doesn't compress scores artificially. For frontier model selection, this is the strongest single composite signal in the public scope.
SWE-bench Verified still moves. Mythos Preview at 93.9%, Opus 4.7 at 87.6%, GPT-5.3 Codex at 85.0%, Gemini 3.1 Pro at 80.6%. That is a 13-point span across the top four labs, which is more than enough to read. The contamination concern is real (the issues come from public repos crawled before benchmark release) but the trend is also real, and Anthropic specifically owns this benchmark in a way that doesn't match its other rankings, which is worth knowing if your workload is coding-heavy. The frontier-model April 2026 ranking goes deeper on which lab leads which axis.
ARC-AGI-2 still has headroom. Top scores at 77-85% leave roughly fifteen points to the human pass-2 ceiling, and the private eval split keeps contamination low. It is no longer the "frontier scores zero" benchmark it was in March 2025, but it has not collapsed into the saturation cluster the way GPQA Diamond has. ARC-AGI-3 picks up where it left off.
GDPval-AA carries the agentic signal. Artificial Analysis's pairwise economic-task leaderboard shows Claude Opus 4.7 at 1753 Elo against Gemini 3.1 Pro Preview at 1314, a 439-Elo gap that maps to a roughly 92% expected win rate in head-to-head agentic deliverables. That is enormous, and it is the single best counterweight to "Gemini ties for first on the Intelligence Index" framing, which the Intelligence Index decomposition piece walks through in detail.
The benchmarks that are good for cocktail-party headlines and bad for model selection in April 2026: GPQA Diamond, MMLU, MMLU-Pro, HumanEval, AIME 2025. The first three are saturated, the last two are saturated and contaminated. Reading them as discriminative is a category error.
The anti-pattern: ClockBench
The single sharpest illustration of why all four questions matter is a benchmark you may have never heard of.
ClockBench was built by Alek Safar to test whether multimodal models can read analog clock faces. Thirty-six distinct clock designs, 180 total clocks, 720 questions covering reading time, adding and subtracting time, rotating hands, and shifting time zones. Adult human accuracy: 90.7%. Top model: GPT-5.4 High at 50.6%. Stanford's 2026 AI Index Report cites the benchmark as the canonical example of the "jagged frontier." The same lab whose model just won gold at the 2025 International Mathematical Olympiad with a 35-of-42 score cannot reliably tell time on a clock face a six-year-old reads in two seconds.
ClockBench is the perfect anti-example. Run the four questions on it.
What does it measure? Visual perception of clock-hand position translated into time. Narrow, specific, real.
What is the human baseline? Roughly 90%, well above frontier model scores around 50%.
How contaminated is the training data? Almost certainly low. There is no public dataset of analog-clock-face-to-correct-time pairs at meaningful scale that frontier models would have seen during pretraining.
Is it saturated? Not even close. The 40-point gap between human and top-model leaves enormous room for the benchmark to discriminate as visual reasoning improves.
ClockBench is the benchmark frontier models cannot game. It is also the benchmark frontier models do not put on launch slides. The four-question filter, applied consistently, surfaces benchmarks like this and lets you see where the actual capability gaps live, instead of where the marketing decks point.
How to evaluate for your own workload
Three rules of thumb if you actually need to pick a model for a real workload.
Don't trust composite indices in your decision domain. AA's Intelligence Index averages ten components across Agents, Coding, General, and Scientific Reasoning. If your workload is one of those four, the other 75% of the composite is dilution. Pull the per-category sub-scores and ignore the composite. AA publishes them on the methodology page.
Build a benchmark for your task. The most underrated move in 2026 is spending one afternoon assembling 50-100 representative tasks from your actual workload, running them through three frontier models, and grading the outputs blind. That is more information than any public leaderboard will give you, because it is contamination-free by construction and the human baseline is "what your team currently produces," which is the only baseline that matters for your decision.
Treat any one-point gap on a saturated benchmark as a tie. A 94.3 vs 94.1 GPQA Diamond gap is run-to-run noise. So is 88 vs 84 on MMLU. Reserve actual discrimination for benchmarks where the gap between top and middle is larger than run-to-run variance: HLE, GDPval-AA, ARC-AGI-2, SWE-bench Verified, and the components inside AA's composite that are still moving.
If you remember nothing else from this piece: a benchmark number is a measurement of one specific thing under one specific methodology at one specific point in time. The headline is always shorter than the test card. Read the test card.
Frequently asked questions
What does it mean when a benchmark is "saturated"?
A benchmark is saturated when the leading models cluster so tightly at the top that the benchmark can no longer rank them reliably. GPQA Diamond is the textbook April 2026 example: the top four frontier models sit within 0.5 percentage points (Mythos Preview 94.6%, Gemini 3.1 Pro 94.3%, Opus 4.7 94.2%, Gemini 3.1 Pro Preview 94.1%) on a 198-question test where one question is roughly 0.5 percentage points. The 95% confidence interval on any single run is wider than the gap between the leading models, so the leaderboard order is methodology variance rather than capability difference. MMLU saturated in 2024 at 88+%; Artificial Analysis dropped MMLU-Pro from its Intelligence Index v4.0 in January 2026 for the same reason.
Are benchmark scores contaminated by training data?
Yes, often. MMLU-CF (Microsoft's contamination-controlled rebuild) showed top model accuracy dropping 14-16 percentage points compared to original MMLU. A 2024-2025 lexical study found 13.8% contamination across sampled MMLU questions. GSM8K accuracy dropped up to 13% when contaminated examples were removed in a 2023 study. The benchmarks that resist contamination publish private hold-outs (HLE) or rolling refresh (LiveBench), or use semi-private and private eval splits (ARC-AGI-2). If a benchmark's full question set has been public for years and predates the model's training cutoff, presume contamination unless the test paper proves otherwise.
Why did frontier models go from 0% to 77% on ARC-AGI-2 in one year?
ARC-AGI-2 launched March 24, 2025 with frontier scores at o3-preview-low 4%, o1-pro 1%, o3-mini-high 0%. That is where the "AI scores 0% on novel reasoning" framing came from. In the thirteen months since, the frontier moved through reasoning-chain training, refinement loops, and multimodal scaling. By April 2026, Gemini 3.1 Pro hits 77.1% on Google's own model card, GPT-5.5 reportedly hits 85% per llm-stats, and ARC Prize launched ARC-AGI-3 to restore the 0%-frontier headroom that ARC-AGI-2 used to provide. The ARC Prize 2025 technical report (published January 2026) credits "the emergence of the refinement loop" as the year's defining theme.
Is ClockBench a real benchmark?
Yes. ClockBench was built by researcher Alek Safar and consists of 36 distinct clock face designs, 180 total clocks, and 720 questions across four task types: reading time, adding/subtracting time, rotating hands, and shifting time zones. Top model GPT-5.4 High scores 50.6% versus 90.7% adult human accuracy. Stanford's 2026 AI Index Report cites ClockBench as evidence of the "jagged frontier" framing: the same models that earned gold-medal-level scores at the 2025 International Mathematical Olympiad cannot reliably read analog clock faces. It is one of the cleanest examples of a contamination-low, unsaturated, narrow benchmark that frontier models genuinely struggle with.
Which AI benchmarks are still meaningful in April 2026?
Four that still discriminate among frontier models: Humanity's Last Exam (top scores 38-46%, broad subject coverage, private hold-out, peer-reviewed in Nature January 2026); GDPval-AA (Artificial Analysis's pairwise economic-task leaderboard, where Opus 4.7 leads Gemini 3.1 Pro by 439 Elo on agentic deliverables); SWE-bench Verified (top scores spread 13 percentage points across labs, real GitHub issues); and ARC-AGI-2 (top scores 77-85% with human pass-2 ceiling at 100%, novel reasoning preserved by private eval splits). The benchmarks to discount in 2026 model selection: GPQA Diamond, MMLU, MMLU-Pro, HumanEval, AIME 2025 (saturated, contaminated, or both).
How should I actually evaluate AI models for my own use case?
Build a benchmark for your task. Spend an afternoon assembling 50-100 representative tasks from your actual workload, run them through three frontier models, grade the outputs blind. That is more information than any public leaderboard will give you, because it is contamination-free by construction and the human baseline is "what your team currently produces," which is the only baseline that matters for your decision. Public benchmarks are useful for setting capability floors (no model below 80% on SWE-bench Verified is shipping production code on its own) but they are weak for choosing among the top three frontier labs in any given category. The four-questions framework (what does it measure, what's the human baseline, how contaminated is the data, is it saturated) is the filter for reading any leaderboard claim before it influences a decision.
