
The "best AI model" question used to have a clean answer. In April 2026 it does not. Three models now sit tied at the top of the Artificial Analysis Intelligence Index, a fourth is locked behind a cybersecurity consortium, and the open-source tier just landed six points off the frontier at a fraction of the price. Anyone handing you a single leader chart is selling you narrative, not data.
The short answer, in real numbers
Claude Opus 4.7, GPT-5.4, and Gemini 3.1 Pro Preview are tied at an Intelligence Index score of 57 on Artificial Analysis. That is three models, not two. The Opus 4.7 tie is two days old as of this writing: Anthropic shipped the model on April 16, 2026, lifting Opus from 53 into the top slot alongside OpenAI and Google. Claude Opus 4.6, the previous Anthropic flagship, stays at 53. On SWE-bench Verified, Opus 4.7 now leads everyone public at 87.6%, with Opus 4.6 at 80.8%, Gemini 3.1 Pro at 80.6%, and Claude Sonnet 4.6 at 79.6%.
Claude Mythos Preview exists, and it is not on any public leaderboard. Anthropic restricted Mythos to Project Glasswing partners in cybersecurity and published isolated benchmark results only: SWE-bench 93.9%, USAMO 97.6%. The model is not API-available to the general public, so Artificial Analysis cannot score it. A deliberate product decision, not a measurement gap.
The open-source tier has closed most of the distance. GLM-5.1 from Zhipu AI scores 51 on the Intelligence Index under an MIT license. GLM-5 sits at 50. MiniMax-M2.7 also hits 50. Kimi K2 Thinking from Moonshot scores 41. DeepSeek V4 claims 80 to 85% on SWE-bench, unverified. The gap between closed frontier (57) and top open-weight (51) is six points on the composite index, narrower on specific benchmarks, and wider on coding depth. Per-token, the open-source tier runs at 5× to 20× less than the closed frontier.
| Model | Intelligence Index | SWE-bench Verified | Input price / 1M | Output price / 1M | Context (input) | Access |
|---|---|---|---|---|---|---|
| Claude Opus 4.7 (Max) | 57 | 87.6% | $5.00 | $25.00 | 1M | Claude API, Bedrock, Vertex, Foundry |
| GPT-5.4 (xhigh) | 57 | ~80% | $2.50 | $15.00 | 1.1M | OpenAI API |
| Gemini 3.1 Pro Preview | 57 | 80.6% | $2.00 | $12.00 | 1M | Google AI Studio, Vertex AI |
| Claude Opus 4.6 (Max) | 53 | 80.8% | $5.00 | $25.00 | 1M | Claude API, Bedrock, Vertex |
| Claude Sonnet 4.6 | — | 79.6% | $3.00 | $15.00 | 1M (beta) | Claude API, Bedrock, Vertex |
| Grok 4.20 0309 v2 (Reasoning) | 49 | ~75% (self-reported) | $3.00 | $15.00 | 256K | xAI API |
| Claude Mythos Preview | Not listed | 93.9% (per red team paper) | Project Glasswing only | Project Glasswing only | Restricted | Consortium access |
| GLM-5.1 (Reasoning) | 51 | — | $1.00 | $3.20 | 200K | MIT license, chat.z.ai |
| GLM-5 (Reasoning) | 50 | 77.8% | $1.00 | $3.20 | 200K | MIT license |
| Kimi K2 Thinking | 41 | 71.3% | $0.60 | $2.50 | 256K | Modified MIT |
What the three-way tie at 57 actually means
Three frontier models arriving at the same composite score through different paths is the story of this quarter. The Artificial Analysis Intelligence Index v4.0 is a composite of ten evaluations: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond, and CritPt. A single integer rolls all ten up. When Opus 4.7, GPT-5.4, and Gemini 3.1 Pro Preview each score 57, they are agreeing on the destination and disagreeing on the route.
Gemini gets there by leading reasoning-heavy and research-science evaluations such as GPQA Diamond and Humanity's Last Exam, at the lowest per-token cost on the frontier. GPT-5.4 balances composite strength with agentic tool use and a deep tradition on the long-context end. Opus 4.7 gets there by pushing coding-agent benchmarks hard: SWE-bench Verified jumped from 80.8% on Opus 4.6 to 87.6%, SWE-bench Pro went from 53.4% to 64.3%, and Anthropic added a new xhigh effort level between high and max to let the model lean harder into deliberation when needed.
Artificial Analysis publishes the score as an integer 57 for all three. If a secondary source quotes decimals like 57.17 or 57.18, treat those as unpublishable numbers the source made up to break a tie that did not exist. The tie is the point.
The fourth frontier model is Claude Mythos Preview. Anthropic's red-team paper reports SWE-bench 93.9% and USAMO 97.6%, a generational leap on specific benchmarks. But Mythos is only available through Project Glasswing, Anthropic's cybersecurity consortium, and does not surface on any public leaderboard. The product decision is explicit: CNBC reported Anthropic rolling out Opus 4.7 on the same day (April 16) precisely because it ships less risky capability than Mythos, and internal policy keeps Mythos in consortium testing rather than general access. You can read Artificial Analysis and you can read the Anthropic red-team paper, but you cannot compare them on the same axis because the rulers are different.
What each model actually wins
Go benchmark by benchmark and the leaders are not consistent.
SWE-bench Verified. Claude Opus 4.7 at 87.6% is the new public record, comfortably clear of Opus 4.6's 80.8% and Gemini 3.1 Pro's 80.6%. GPT-5.4 sits near 80% (OpenAI does not publish a clean figure on its own card). Sonnet 4.6 at 79.6% is a strong mid-tier score, though some secondary posts have described Sonnet 4.6 as the SWE-bench leader. It isn't. Both Opus tiers beat it, and the 4.7 release widened the Anthropic internal gap again.
GPQA Diamond. Opus 4.7 at 94.2% retakes this from Gemini 3.1 Pro at 94.3%, a 0.1-point difference that is essentially noise. GPT-5.4 posts 92.0% per third-party harness. Kimi K2 Thinking at 84.5% is the best open-source result on graduate science. GLM-5 scores 68.2%. The open-source top three span a huge range.
Humanity's Last Exam. Gemini 3.1 Pro Thinking High leads Scale AI's HLE leaderboard at 46.44%, with GPT-5.4 Pro at 44.32% and Opus 4.7 at 54.7% with tools (not directly comparable because tool-use rules differ across runs). Kimi K2 Thinking hits 44.9% with tools, closer to Gemini and GPT than to Opus 4.7 on the lifted variant. HLE is one of the benchmarks where the open-source frontier is a single percentage point off the closed frontier, once you grant tool use to everyone.
ARC-AGI-2. Gemini 3.1 Pro at 77.1% is the public leader. Grok 4.2 reportedly broke 10% (15.9%) in February 2026, a big jump for the xAI lineage but still a long way off the frontier. OpenAI has not published an ARC-AGI-2 score for GPT-5.4. Opus 4.7's ARC-AGI-2 number did not ship in Anthropic's launch material.
LMArena Elo. As of the most recent public scrapes (the primary site has been fetch-hostile for months, so the numbers move), Claude Opus 4.6 Thinking held the #1 slot around 1504 Elo before Opus 4.7 shipped; Gemini 3.1 Pro Preview was #3 at roughly 1493, and GPT-5.4 High near 1484. Arena rewards whatever the median human voter thinks "better" means on a fresh prompt. That is a different capability vector from Intelligence Index reasoning depth, and no lab controls it directly.
Pricing. Gemini 3.1 Pro is the cheapest among the three-way tie by a real margin. Per million tokens, Gemini runs $2 input and $12 output. GPT-5.4 is $2.50 and $15. Opus 4.7 and 4.6 both sit at $5 and $25. Running the full Intelligence Index end-to-end cost Artificial Analysis $892 on Gemini 3.1 Pro, roughly $2,304 on GPT-5.2, $2,486 on Opus 4.6 at max reasoning, and $4,406 on Opus 4.7 (the most expensive reasoning evaluation in the cohort because Opus 4.7 uses more output tokens for deliberation).
So the headline (three models tied at 57) is real. The follow-through is that you pay almost 5× to run the same composite on Opus 4.7 versus Gemini 3.1 Pro. Quality parity, price dispersion. If you are building production systems at scale, that gap decides margin.
The open-source tier that just caught up
The story of 2026 isn't who sits at 57. It is how close the open-weight frontier landed.
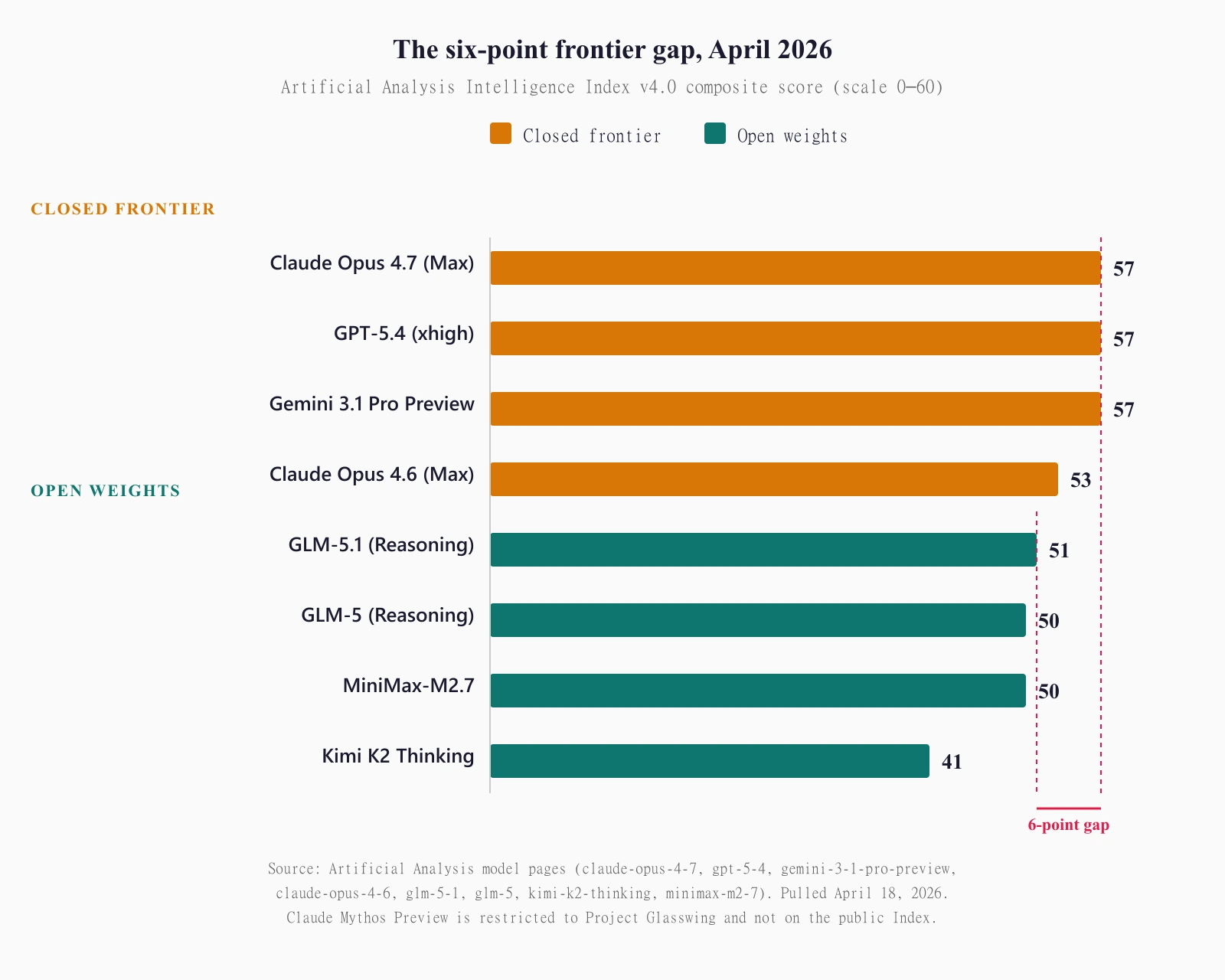
GLM-5 and GLM-5.1 (Zhipu AI). GLM-5 shipped February 11, 2026 under MIT license. 744 billion total parameters, 44 billion active through a 256-expert MoE with 8 selected per token, trained for 28.5 trillion tokens on 100,000 Huawei Ascend 910B chips. No NVIDIA GPUs. That last detail matters more than the benchmark scores. GLM-5 posts 50.4% on Humanity's Last Exam with tools, 77.8% on SWE-bench Verified, 68.2% on GPQA Diamond, and 88.7% on AIME 2025. Pricing is $1 input and $3.20 output per million tokens, roughly a fifth of Opus pricing. GLM-5.1, released April 7, leans harder into long-horizon agentic coding and pushes the Intelligence Index to 51, the highest open-weight score recorded so far. Both are MIT. You can download the weights and run them on your own silicon.
Kimi K2 Thinking (Moonshot AI). Released November 6, 2025 with a 1-trillion-parameter MoE (32B active through 384 experts, 8 selected per token), modified MIT license, 256K context. Intelligence Index 41. Benchmark profile: HLE 23.9% no tools / 44.9% with tools / 51.0% heavy, SWE-bench Verified 71.3%, LiveCodeBench V6 83.1%, GPQA 84.5% no tools, BrowseComp 60.2%. Pricing $0.60 input / $2.50 output. The famous stat, reported by CNBC: the model cost $4.6 million to train. Four and a half million dollars for a model that clears GPQA at 84.5%. That is the part that keeps showing up in investor memos.
DeepSeek V4. Early March 2026 release. 1 trillion total parameters, 32 to 37 billion active depending on source, 1 million token context, pricing projected at $0.14 / $0.28 per million tokens. Projected is doing work there. DeepSeek's current API still lists V3.2 at $0.28 / $0.42. V4 benchmark claims of 80 to 85% on SWE-bench Verified trace to pre-release internal runs or leaks, not independent harnesses. If those hold up, the SWE-bench split between DeepSeek and closed-frontier shrinks to near zero at a fifteenth of the price. Independent verification is the piece still missing.
Meta Llama 4 Scout. Ten million token context window, 17 billion active parameters through 16 experts, 109 billion total. Fits on a single H100 with Int4 quantization. The caveat you do not see in most Llama 4 summaries: Scout released April 5, 2025. A year old in an industry where a year is roughly four model generations now. The 10M context is still industry-leading for an open model that fits on one GPU. The benchmark scores are not frontier.
Alibaba Qwen 3.5-9B. Released March 2, 2026 under Apache 2.0. 9 billion parameters. GPQA Diamond 81.7, beating OpenAI's gpt-oss-120B at 80.1. Roughly 13× fewer parameters for a better score. The Qwen 3.5 small series runs on a 6GB-RAM Android phone. For consumers, that is the shape of edge AI in Q2 2026.
The headline on open-source, put as plainly as possible: six points below the composite frontier, a tenth the price, weights you can download, on hardware you can buy. For a range of workloads that do not need the top 6 points of composite reasoning depth, the right default for 2026 is no longer a closed API call.
The Stanford AI Index 2026, and the 255-release misread
The Stanford AI Index 2026, released April 13, is the single-best institutional pulse check on where the field actually is. Worth reading in full. The line that will show up in every summary deck this quarter: as of March 2026, the top American model leads the top Chinese model by just 2.7% on the Arena benchmarks Stanford tracks. Last year that gap was in double digits. The second line: generative AI has hit 53% global population adoption in three years, faster than personal computing or the internet did at the same point in their curves. The third: 90%+ of notable frontier models in 2025 came from industry, and 87 of 89 notable models in their 2025 count came from commercial organizations. Academia is now a minority voice in frontier AI by a wide margin.
A Q1 2026 statistic you will see repeated everywhere: "255 model releases from major organizations in Q1 2026 alone." It is a useful number. It is also not a Stanford AI Index 2026 figure. It traces to LLM Stats, which tracks 500+ models in real time, and gets amplified through industry-news roundup coverage. The Stanford report says "industry produced over 90% of notable frontier models in 2025" without publishing a 255 figure for Q1 2026. I'm flagging the attribution because a mistaken Stanford citation lets a reader assume peer-reviewed rigor where none exists. The 255 number is an aggregator count, not the Index's analytical output.
On global AI investment: 2025 came in at $581 billion (up from $253 billion in 2024), with $344 billion from the United States. More than the GDP of most OECD countries, pouring into a single technology layer in twelve months. The Stanford report is frank about the sustainability question: this level of capex cannot compound without a commercial payoff, and the payoff so far has concentrated in a small number of enterprise SaaS lines.
Which model to actually use (a decision framework)
Benchmarks do not tell you which model to pick. Your workload shape does. Here is how I'd draw the decision tree in April 2026.
Coding agent that touches real repositories. Claude Opus 4.7 is the clean answer. 87.6% on SWE-bench Verified, 64.3% on SWE-bench Pro, 69.4% on Terminal-Bench 2.0. The token-efficiency improvements in the April 16 release matter here too: Anthropic reported a third fewer tool-call errors versus Opus 4.6 on complex multi-step workflows. For the same workload a quarter earlier, I would have said Opus 4.6 or Sonnet 4.6 depending on budget. Opus 4.7 widens the answer.
Long-document reasoning and research. Gemini 3.1 Pro. It leads GPQA Diamond and Humanity's Last Exam Thinking High, the context window handles real research corpora, and the pricing is the lowest on the frontier tier. If you are running an analyst workflow over 800-page PDFs, the cost-per-query math is not close. Where it matters, Gemini 3.1 Pro leads 6 of 10 Intelligence Index evaluations.
Agentic tool use across complex stacks. GPT-5.4 at xhigh effort. The Artificial Analysis τ²-Bench Telecom and IFBench scores favor GPT-5.4's agentic loop behavior. 1.1 million token context. The OpenAI API tooling ecosystem is more mature than either competitor on function-calling edge cases.
Cybersecurity-sensitive agentic work with pre-approved consortium access. Claude Mythos Preview through Project Glasswing, if you qualify. Everyone else: Claude Opus 4.7 for the next-best public ceiling. OpenAI's Trusted Access for Cyber is the other gated pathway for the GPT-5.4 side of the aisle.
Production systems at high token volume where you control the hosting. The open-source tier. GLM-5.1 for the composite ceiling, DeepSeek V4 for the pricing floor once full release benchmarks are independent, Kimi K2 Thinking for the agentic/math profile at a $4.6M training budget that you can't get anywhere else. A real number to anchor the picture: per-token cost on GLM-5 (output) runs at roughly 13% of Opus 4.7's output price. At a million output tokens per day, that is the difference between shipping a feature and killing it at the quarterly review.
Edge and on-device. Qwen 3.5-9B is the frontier for now. A graduate-science benchmark result that beats OpenAI's 120B open model, running on a 6GB Android phone, Apache 2.0. For consumer-device inference, that shape of model is going to define Q2.
The composite leaderboard is useful. It is not a buying guide. A serious buying guide has to look at which benchmark maps to your workload, whether the model is publicly API-available at all, what the hosted cost is at your actual volume, and what the open-weight alternative looks like at five to fifteen times less per token. The labs have been competing on benchmark dominance because dominance is publishable. The buyers are starting to care about the other four factors more.
What the top-ten lists keep missing
One artifact of the 2026 AI news cycle worth calling out: the "leader" chart in most launch coverage comes straight from the launching lab's benchmark basket, and comparison models often have missing scores in that basket that get rendered as zero or absence. When Google announced Gemini 3.1 Pro as leading 13 of 16 benchmarks, SmartScope ran the footnote and found GPT-5.3-Codex had only published scores for 2 of those 16. In the other 14, Gemini was winning against a blank column. That isn't fraud. It is a genre convention of launch posts. The same thing happens on the other side: the Opus 4.7 launch post compares against Opus 4.6, not against GPT-5.4 or Gemini 3.1 Pro directly, because the head-to-head comparisons are messier. Check the footnotes before you let the headline bar graph set the frame.
A related artifact: the Anthropic Intelligence Score that keeps appearing in third-party coverage is not the same thing as the Artificial Analysis Intelligence Index. Neither is the Stanford Capabilities Index from the AI Index 2026. Three composite scores, three methodologies, three different universes. When you see a "frontier ranking" piece, the first question is which composite it uses and whether the authors converted between them or cited one as if it were the other. Cross-composite conversion is not valid.
The last and biggest miss in most coverage: Claude Mythos Preview simply does not show up on the public composite leaderboards at all. Readers infer from absence that Mythos is behind Opus 4.7. The restricted-access design makes the question unanswerable. Mythos is ahead on the isolated benchmarks it reports (SWE-bench 93.9% is four to seven points above any public model), but the composite index can only measure models the public can run. The right posture is "Mythos exists outside the public ranking and that is on purpose."
For the underlying product-policy logic of why Anthropic keeps Mythos in consortium testing while shipping Opus 4.7 to everyone, the Mythos Preview parameters and benchmark breakdown covers the disclosed-versus-speculated split and the 244-page system card details. The Anthropic-OpenAI cybersecurity split between Mythos and GPT-5.4-Cyber is the other half of the access story. OpenAI's Trusted Access for Cyber program walks through the gating mechanism on the OpenAI side. And the Gemini 3.1 Pro benchmark breakdown decomposes the Google composite across GPQA, HLE, LMSys, and FrontierMath.
What to watch in Q2 2026
Three threads to track through June.
DeepSeek V4 full release and independent benchmarks. If V4 full launches with SWE-bench Verified in the 80 to 85% range and the $0.14 / $0.28 pricing holds, it is the biggest cost compression the frontier has seen since mid-2024. The open-question is independent harness runs, not DeepSeek's internal numbers. Watch LMSYS, Scale AI, Epoch AI for third-party confirms.
GLM-5.x and Zhipu's trajectory on Huawei Ascend. Zhipu trained GLM-5 on 100,000 Huawei 910B chips without NVIDIA. If GLM-5.2 or a successor model clears 55 on the Intelligence Index, the US export-control calculus has to get revised. Not in the lab's favor.
The Mythos access expansion question. CNBC's framing of Opus 4.7 as "less risky than Mythos" is the soft edge of a harder product-policy argument: does Anthropic ever open Mythos to general API access, and on what timeline? Every Glasswing-partner case study that drops will update the probability. Watch Bishop Fox and the AISI for external evaluation updates.
One thread I would deliberately not watch: another lab announcing a new tied-at-top Intelligence Index score of 57. That has now happened three times in roughly eight weeks. The news will not be a fourth 57. The news will be a model that moves to 60 or a model that redefines the composite itself. If Artificial Analysis bumps to v5.0 of the Intelligence Index and changes the ten evaluations, all the April 2026 scores get reread overnight.
The race is not settled. The race is compressed. Four frontier-tier models within four points of each other, one model sitting off the board on purpose, and an open-weight tier six points behind at a fraction of the price. Anyone telling you the field is won is reading a version of the chart that will not survive Q2.
Frequently asked questions
What are the top frontier AI models in April 2026?
Three models are tied at the top of the Artificial Analysis Intelligence Index at 57: Claude Opus 4.7 (released April 16, 2026), GPT-5.4 (xhigh), and Gemini 3.1 Pro Preview (released February 19, 2026). Claude Opus 4.6 sits at 53. Claude Mythos Preview is restricted to Project Glasswing partners and does not appear on the public index. The open-source leader is GLM-5.1 at 51.
Which AI model is best at coding in April 2026?
Claude Opus 4.7, released April 16, 2026, leads public SWE-bench Verified at 87.6%, with SWE-bench Pro at 64.3% and Terminal-Bench 2.0 at 69.4%. For comparison, Claude Opus 4.6 was at 80.8% on SWE-bench Verified, Gemini 3.1 Pro at 80.6%, and Claude Sonnet 4.6 at 79.6%. Claude Mythos Preview reports 93.9% on SWE-bench in Anthropic's red-team paper, but Mythos is not publicly accessible through Anthropic's API.
How does the open-source AI tier compare to closed frontier models?
On the Artificial Analysis Intelligence Index, the closed frontier sits at 57 (Opus 4.7, GPT-5.4, Gemini 3.1 Pro). The open-source top is GLM-5.1 at 51, followed by GLM-5 and MiniMax-M2.7 at 50. That is a six-point composite gap. On specific benchmarks the gap is narrower: GLM-5 scores 77.8% on SWE-bench Verified against Opus 4.6's 80.8%, a three-point gap. Per-token, the open-source tier runs roughly 5× to 20× cheaper than closed frontier APIs.
Is Claude Opus 4.7 better than Claude Mythos Preview?
On public SWE-bench the answer is no: Mythos at 93.9% is above Opus 4.7 at 87.6%. On the Artificial Analysis Intelligence Index the comparison cannot be made because Mythos is not on the public leaderboard. Anthropic restricts Mythos to the Project Glasswing cybersecurity consortium. Opus 4.7 is Anthropic's most capable generally available model as of April 16, 2026; Mythos is a more capable model that is not generally available by design.
How much does it cost to run a frontier AI model in 2026?
Per million tokens (April 2026 API prices): Gemini 3.1 Pro runs $2 input / $12 output. GPT-5.4 runs $2.50 / $15. Claude Opus 4.7 and 4.6 both run $5 / $25. Grok 4 runs $3 / $15. The open-source tier runs much cheaper: GLM-5 is $1 / $3.20, Kimi K2 Thinking is $0.60 / $2.50, DeepSeek V4 is projected at $0.14 / $0.28 (not yet confirmed at public release). Running the full Artificial Analysis Intelligence Index evaluation cost $892 on Gemini 3.1 Pro, $2,304 on GPT-5.2, $2,486 on Claude Opus 4.6, and $4,406 on Claude Opus 4.7 at max reasoning.
What did the Stanford AI Index 2026 actually say about model counts?
The Stanford AI Index 2026, released around April 13, 2026, reports that over 90% of notable frontier models in 2025 came from industry, with 87 of 89 notable models from commercial organizations (98%). The US released 50 "notable" models in 2025 according to the same report. The commonly cited "255 model releases from major organizations in Q1 2026" statistic is NOT from the Stanford Index. It traces to the LLM Stats aggregator and secondary industry coverage. Stanford's more consequential headline is that the US lead over China narrowed to just 2.7% as of March 2026, and generative AI hit 53% global population adoption in three years.
