
"Which AI is best?" is the wrong question. By April 2026 the frontier is six different ladders propped against six different walls, and the right answer changes by task. The honest question is which model for which job, evaluated against four variables: what you are doing, how good it has to be, how fast you need it, and what you can spend.
This is the framework I actually use, built from sixteen weeks of reporting on this frontier and from production work routing real prompts to real models for real money. It assumes the April 2026 lineup, which has shifted twice while this article was being written: Opus 4.7 GA on April 16, GPT-5.5 on April 23, DeepSeek V4 on April 24, Llama 5 on April 8, GLM-5.1 on April 7. Treat the recommendations as a snapshot. The framework outlives the models.
The four-variable framework
Four inputs. Run any task through them before you pick a model.
Task type. What the model is actually doing. Code generation is a different task from copyediting, which is different from analyzing a PDF, which is different from real-time market reads. Stanford's 2026 AI Index calls this the jagged frontier: the same models that win gold at the International Mathematical Olympiad read analog clocks at fifty-fifty odds. Pick a model that wins at your specific job, not the one that wins on Twitter.
Quality requirement. A draft email and a regulatory filing demand different ceilings. Most of what most teams do does not need the absolute top-of-leaderboard model. The Artificial Analysis Intelligence Index has Opus 4.7, Gemini 3.1 Pro Preview, and GPT-5.4 xhigh tied at 57. The next tier sits at 50-54. The gap is real but smaller than the price gap suggests.
Latency sensitivity. Code review in an IDE needs sub-second response. A nightly batch job does not. Reasoning models trade speed for depth. Grok 4.20's four-agent consensus runs at 89.9 tokens per second; Opus 4.7 in extended-thinking mode can be slower by an order of magnitude.
Budget. Output tokens dominate the bill in any agent that writes code or long documents. GPT-5.5 Pro lists at $180 per million output tokens. DeepSeek V4-Flash lists at $0.28. That is a 643× ratio. Cost is not a tiebreaker. It is a category.
The real April 2026 frontier ranking, beyond marketing headlines walks the data with the receipts.
The radar chart below shows what "different models win different jobs" looks like in one frame. Five frontier models, six task categories, scored 0 to 100 with each axis anchored to a published benchmark. No single shape covers every direction.
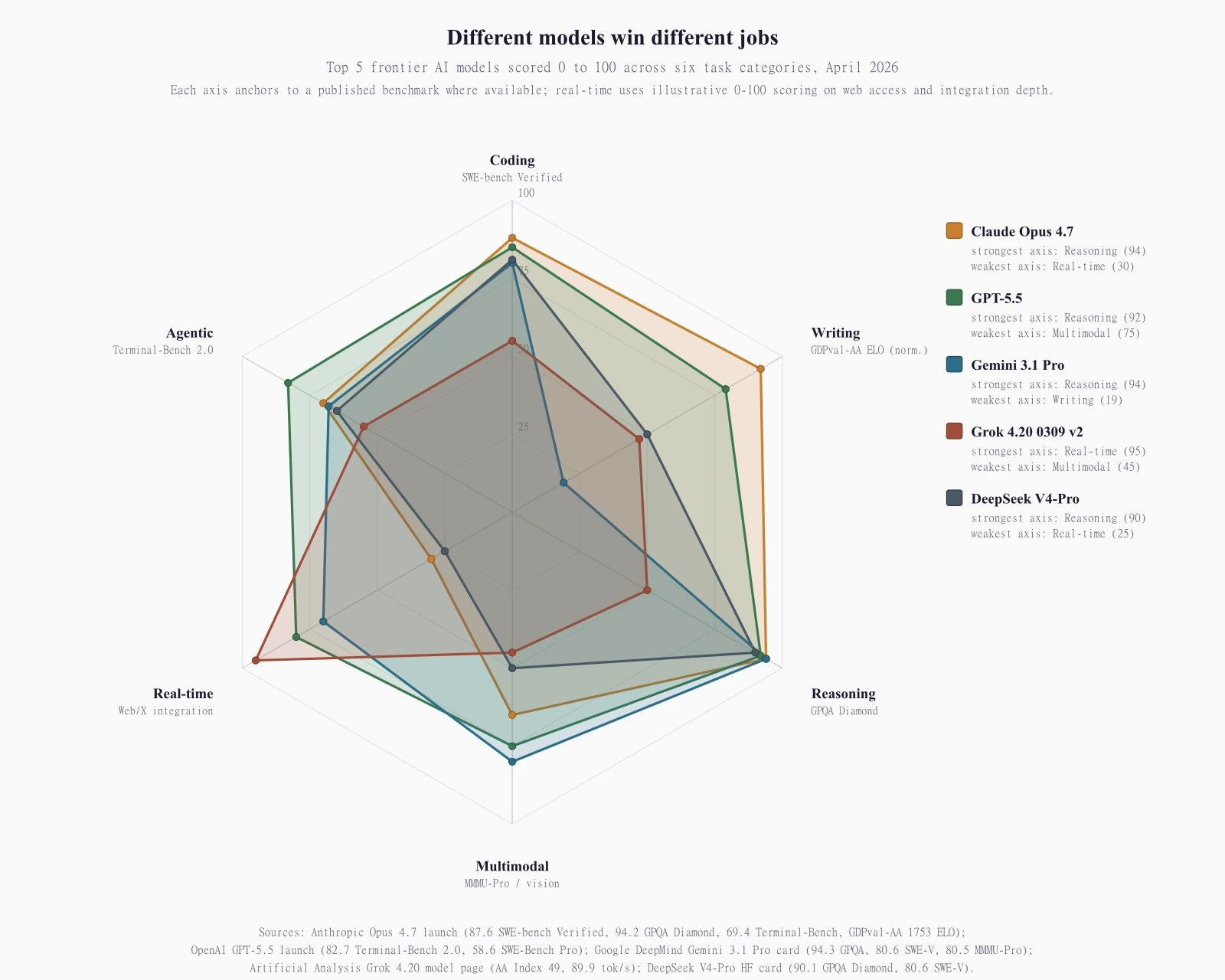
The table below maps tasks to recommendations. Read it as the short version; the next nine sections work each row.
| Task category | Primary pick | Secondary / alternative | Budget option | Anchor benchmark |
|---|---|---|---|---|
| Coding (real GitHub work) | Claude Opus 4.7 | GPT-5.5 (Terminal-Bench focus) | Cursor Composer 2 / Sonnet 4.6 / GLM-5.1 | Opus 4.7 SWE-bench Verified 87.6% |
| Writing and editing | Claude Sonnet 4.6 | Claude Opus 4.7 (long-form / argument-heavy) | Haiku 4.5 / Gemini 3 Flash | Sonnet 4.6 GDPval-AA ELO 1675 |
| Research and reasoning | Gemini 3.1 Pro | Claude Opus 4.7 / GPT-5.5 | Gemini 3 Flash | Gemini GPQA Diamond 94.3%, ARC-AGI-2 77.1% |
| Multimodal (image / video / audio in) | Gemini 3.1 Pro | GPT-5.5 (omnimodal) | Gemini 3 Flash | Gemini MMMU-Pro 80.5%, Video understanding leadership |
| Real-time information | Grok 4.20 0309 v2 | Gemini 3.1 Pro with grounding | Grok 4 Fast (search-priced) | Grok 2M context, X integration, 4-agent consensus |
| Agentic workflows | Claude Opus 4.7 | GPT-5.5 (Terminal-Bench 82.7%) | DeepSeek V4-Pro / Kimi K2.6 | Opus 4.7 GDPval-AA ELO 1753 (top of real-work eval) |
Task category 1: Coding
"Coding" hides at least three different jobs.
For real GitHub-issue resolution, Claude Opus 4.7 leads. SWE-bench Verified 87.6%, SWE-Bench Pro 64.3%. Both numbers landed at the April 16 launch. The previous flagship sat at 80.8% Verified; Anthropic closed nearly seven percentage points in a single minor version on the hardest production-code benchmark anyone runs. The full breakdown of how this lifted the SaaS-build economics for Claude Code on Pro and Max plans covers what changed in practical terms.
For complex command-line workflows and long-horizon agentic coding, GPT-5.5 wins narrowly. Terminal-Bench 2.0 at 82.7% is state-of-the-art at launch, edging Mythos Preview by a sliver. OpenAI built GPT-5.5 specifically for tasks where a model has to plan, use tools, recover from failures, and keep going for hours.
For high-volume coding or self-hosted setups, the open frontier is genuinely competitive. GLM-5.1 from Z.ai posts 58.4% on SWE-Bench Pro, ahead of GPT-5.4's 57.7% and Opus 4.6's 57.3%. Cursor Composer 2 at $0.50 input / $2.50 output per million tokens is frontier-class on coding for a fraction of the flagship cost. The honest read on open-source vs closed-source for the bulk-inference picture frames the trade.
The trap: do not pick a coding model on a single benchmark. Opus 4.7 wins SWE-Bench Pro by 5.7 points over GPT-5.5. GPT-5.5 wins Terminal-Bench 2.0. Both are correct. Different slices of coding reward different model designs.
Task category 2: Writing and editing
Sonnet 4.6 is the writing model nobody calls a writing model. On Artificial Analysis's GDPval-AA real-work-task leaderboard, Sonnet 4.6 sits at 1675 ELO. GPT-5.4 xhigh sits at 1674. Opus 4.6 at 1619. Sonnet 4.6 outscores GPT-5.4 on real economic work despite costing $3 input / $15 output versus GPT-5.4's $2.50 / $15. The 79-ELO gap between Opus 4.7 (1753) and the field corresponds to roughly a 61% expected win rate, which is the practical difference between "this is fine" and "this lands."
For drafts, edits, marketing copy, and most knowledge work that requires good prose, Sonnet 4.6 is the correct default. For long-form work where the argument has to hold across thousands of words and the model needs to maintain a single voice across hundreds of paragraphs, Opus 4.7 earns its premium. Anthropic architected Opus 4.7 for "long-running, asynchronous" work, which translates directly.
For high-volume copy where throughput matters more than draft quality, Haiku 4.5 at $1 / $5 per M runs four to five times faster than Sonnet at a fraction of the cost. Gemini 3 Flash at $0.50 / $3 is the Google equivalent. Both post 90%+ on GPQA Diamond. The cost-vs-quality trade for free and paid AI tools across building workflows covers the practical economics.
A flag here. The single biggest win in my own workflow was setting Sonnet 4.6 as the writing default and routing only heavy long-form pieces to Opus. The flagship-by-default habit is expensive and rarely earned.
Task category 3: Research and reasoning
For research work where the model has to read long documents, hold multiple chains of reasoning, and produce a defensible synthesis, Gemini 3.1 Pro is the right pick.
The numbers are the argument. GPQA Diamond 94.3% on Google's own model card. ARC-AGI-2 77.1%, the highest public score on the benchmark Chollet's team built to defeat language models. SWE-bench Verified 80.6%. Humanity's Last Exam 44.4% no-tools. MMMU-Pro 80.5%. The 1M-token context window at $2 input / $12 output per million tokens is roughly half the price of the equivalent Anthropic or OpenAI tier. Google ran the full Intelligence Index v4.0 evaluation for $892; Anthropic's Opus 4.7 cost $4,406. Same composite score of 57; very different bills. The deeper teardown of Gemini 3.1 Pro across GPQA, HLE, LMSys, and FrontierMath carries every benchmark with attribution.
For unsaturated reasoning where GPQA Diamond no longer discriminates (every frontier model scores within half a percentage point), Humanity's Last Exam is the better signal. Gemini 3.1 Pro Preview leads HLE on Artificial Analysis's run at 44.7%, GPT-5.4 xhigh at 41.6%. The methodology behind why GPQA Diamond is now too saturated to discriminate at the top explains why HLE is load-bearing.
For maximum-quality reasoning where cost is irrelevant, GPT-5.5 Pro at $30 / $180 per M sits above GPT-5.5 standard. Whether the spend is worth it depends on whether the output goes to a customer or back into a pipeline.
Task category 4: Multimodal
Multimodal in practice means three things: image understanding from screenshots and photographs, video understanding from clips, document understanding from scanned PDFs.
Gemini 3.1 Pro is the strongest single choice across all three. Google trained Gemini natively on image, video, and audio from the start, and the model card carries the receipts: 80.5% MMMU-Pro, leadership on long-form video, native audio at $1 per million audio tokens. For document-and-vision work, the same capability that wins academic benchmarks shows up in production: Gemini handles a 200-page PDF with charts in one call.
GPT-5.5 carries forward GPT-5.4's omnimodal architecture: text, image, audio, video in the same call. Competitive on most multimodal benchmarks, top on a few. If your stack already runs on the OpenAI API and the work is mixed-format rather than video-heavy, switching is rarely worth a sub-five-percent gap.
Stanford's 2026 AI Index pulls a useful caution. The same multimodal models that score 90%+ on graduate-level science benchmarks read analog clocks at 50.1% accuracy. The jagged frontier is real. "Multimodal capability" in a vendor blog post does not always translate to "works on your specific images."
Task category 5: Real-time information
The model has to know what happened today, not last quarter. The recommendation is xAI's Grok 4.20 0309 v2, and the reasoning is operational, not benchmark-driven.
Grok 4.20 ships with X (formerly Twitter) integration baked in, including the live posts feed. 2M-token context, the largest of any GA frontier model. $2 input / $6 output per million tokens. Output speed 89.9 tokens per second. The architecture runs four specialized sub-agents in parallel on every query; the consensus vote drops Grok's measured hallucination rate from roughly 12% to 4.2%. On ForecastBench (predicting real-world outcomes) Grok 4.20 ranks #2 overall, ahead of GPT-5 and Claude Opus 4.5.
The trade is on quality. Artificial Analysis Intelligence Index 49 puts Grok 4.20 a full 8 points behind the closed-frontier tie at 57. For tasks where reasoning depth matters more than recency, pick a 57-tier model. For tasks where "what is happening right now in this market" beats "what is the structurally correct analysis," Grok wins by operating on data the other models do not have.
Gemini 3.1 Pro with grounding (Google Search in Vertex AI) is a credible alternative if you are on Google Cloud. Grok 5 has missed its Q1 2026 deadline; xAI now points to a Q2 ship window of May or June. Anyone reading this in late May should re-verify.
Task category 6: Agentic workflows
Long-running agents (the kind that use tools, plan multi-step work, recover from errors, and run for minutes or hours without supervision) are now their own category. The leader is Claude Opus 4.7.
The numbers come from Artificial Analysis's GDPval-AA leaderboard, built from real economic-value-weighted tasks. Opus 4.7 leads at 1753 ELO. Sonnet 4.6 second at 1675. GPT-5.4 xhigh third at 1674. Opus 4.6 fourth at 1619. Gemini 3.1 Pro Preview ninth at 1314. The 439-ELO gap between Opus 4.7 and Gemini 3.1 Pro corresponds to roughly a 92% expected win rate. Composite intelligence indices hide this divergence; the Intelligence Index decomposition story walks why the same 57-tier composite can mask a four-to-one ratio of agentic work quality.
For agentic coding specifically, GPT-5.5's 82.7% Terminal-Bench 2.0 is the right primary. For agentic research and analysis where the agent reads sources, builds citation chains, and produces a report, Opus 4.7 wins.
For self-hosted or cost-sensitive agentic deployments, DeepSeek V4-Pro at 1.6T total / 49B active, 1M context, $1.74 / $3.48 per M, runs frontier-tier on most agentic tasks at roughly one-sixth the cost of Opus 4.7. Kimi K2.6 from Moonshot is the open-source agentic specialist; K3 is expected within weeks.
The routing pattern: multi-model by default
The framework above is not how I actually pick a model. It is how I configure a router that picks for me. Multi-model by default is not a hypothetical; it is the production reality, and it is enabled by specific tools that shipped in the last twelve months.
OpenRouter routes requests across 300+ active models from 60+ providers behind a single OpenAI-compatible endpoint. Edge architecture adds about 25 milliseconds of overhead. Set a primary model, fallback chain, cost ceiling, and routing strategy (cheapest first, fastest first, highest quality first) per request. The OpenRouter Agent SDK adds a callModel function that turns a chat completion into a multi-step agent with tool calls, stop conditions, and cost tracking. Drop-in replacement if you use the OpenAI SDK; one base URL change and your code has access to Opus 4.7, GPT-5.5, Gemini 3.1 Pro, Grok 4.20, DeepSeek V4-Pro, Llama 5, GLM-5.1, and Kimi K2.6 from the same call.
Cursor 3.0's model picker puts GPT-5.5, Opus 4.7, Gemini 3.1 Pro, Grok Code, and Composer 2 in a dropdown inside the IDE, with one-click switching mid-task. Composer 2 at $0.50 / $2.50 is frontier-class on coding at flagship-fraction cost. Most of my code-generation work runs through Composer; review and architectural questions go to Opus 4.7; one-shot specs go to Gemini 3.1 Pro.
Claude Code routes between Sonnet 4.6 and Opus 4.7 from a single Pro or Max subscription via the /model slash command. Subagents run within a session for parallel tasks; Agent Teams coordinate across sessions for parallel review (a lint pass, a security pass, and a fact pass running simultaneously, merging results).
For workflow orchestrators, n8n's advanced-AI nodes ship Claude, OpenAI, Gemini, Grok, Mistral, Ollama, and OpenRouter as first-class providers. Drop them onto the canvas and route by node logic. LangChain.js documents 70+ chat-model integrations. Vercel AI SDK gives you generateText and streamText across @ai-sdk/anthropic, @ai-sdk/openai, @ai-sdk/google, @ai-sdk/xai, @ai-sdk/deepseek, and twenty-plus other provider packages. Switch the model name; the rest of the code does not change.
For self-hosted, OpenWebUI sits on top of any OpenAI-compatible endpoint (Ollama, OpenRouter, vLLM, llama.cpp). One UI, multiple backends, local-and-cloud routing trivially configured.
The pattern that wins in 2026 is not "pick a model." It is "pick a primary, configure a fallback chain, route by cost ceiling and latency budget, monitor by task type." The tools to do this ship today, and most are free or under $20 a month.
Budget-driven selection
If budget is the binding constraint, the math reorganizes the framework.
For volume processing where output tokens dominate the bill, DeepSeek V4-Flash at $0.14 / $0.28 per M is the floor. That is roughly 1/89 the output cost of Opus 4.7 and 1/107 of GPT-5.5. At 100M output tokens per day, V4-Flash bills approximately $10,200 per year; Opus 4.7 at the same volume bills approximately $912,500. The cost ratio is the entire reason "bulk inference" exists as its own category. SCMP characterized DeepSeek V4 pricing as "as much as 97 per cent below OpenAI's GPT-5.5."
For mid-volume work, Gemini 3 Flash at $0.50 / $3 per M is the strongest choice, with frontier-class GPQA Diamond at 90.4% baked in. Haiku 4.5 at $1 / $5 lands close behind on the Anthropic side. Both run modern 2026 reasoning at small-model latency.
For the maximum-quality tier, Mythos Preview is the absolute ceiling for cleared organizations. Eleven external partners through Project Glasswing. SWE-bench Verified 93.9% in Anthropic's red team paper. $25 / $125 per M, five times Opus 4.7's rate. For everyone else (which is everyone, almost) Opus 4.7 at $5 / $25 is the practical maximum, with 1M-token context at standard pricing and the top spot on GDPval-AA. Why Mythos sits in consortium testing while Opus 4.7 ships to everyone traces the deployment-policy split.
The decision tree
The decision tree below is the framework rendered as a flowchart. Start at the top with your task, walk through the four variables, land on a recommendation. The tree assumes the April 2026 lineup; re-check the Anthropic, OpenAI, Google, and xAI release pages before any decision that costs more than $100 a month.

The pattern that holds even as the names drift: route by task type first, quality second, latency third, budget fourth. Models change every six weeks. The decision rules change roughly twice a year. Build your routing on the rules, not the names.
For preference-based ranking that reflects what users actually choose in blind comparisons, the LMSys Arena Elo leaderboard, read honestly is a useful gut check on whether your benchmark-derived pick aligns with human preference data. The two often diverge, and the divergence itself is information.
For specialist routing on cybersecurity work, the Mythos vs GPT-5.4-Cyber comparison covering Anthropic and OpenAI's split deployment philosophies covers the cleared-access pattern. For methodology beneath the recommendations, the four-question framework for reading benchmarks without being fooled is the prerequisite reading. Pick on the framework. Verify on the methodology. Update on the release notes.
Frequently asked questions
What is the single best AI model in April 2026?
There isn't one. Three models tie at 57 on the Artificial Analysis Intelligence Index (Claude Opus 4.7, Gemini 3.1 Pro Preview, GPT-5.4 xhigh) and the composite tie hides material divergence on specific work. Opus 4.7 wins agentic work (GDPval-AA 1753 ELO) by a wide margin. Gemini 3.1 Pro wins reasoning and multimodal. GPT-5.5 wins general-purpose long-horizon coding (Terminal-Bench 82.7%). Mythos Preview wins on the closed-access cybersecurity track. Different jobs, different leaders.
Which model should I use for code generation in 2026?
For real GitHub-issue resolution, Claude Opus 4.7 (87.6% SWE-bench Verified, 64.3% SWE-Bench Pro). For long-horizon agentic coding inside a terminal, GPT-5.5 (82.7% Terminal-Bench 2.0). For high-volume coding at lower cost, Cursor Composer 2 ($0.50/$2.50 per M) or GLM-5.1 (open-source SWE-Bench Pro leader at 58.4%).
Which model is best for research and reasoning tasks?
Gemini 3.1 Pro. 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 80.6% SWE-bench Verified, 44.4% Humanity's Last Exam. $2 input / $12 output per million tokens, with a 1M-token context window. It also runs the Intelligence Index evaluation at roughly half the cost of Anthropic's flagship for the same composite score.
What is the cheapest frontier-tier AI model?
DeepSeek V4-Flash at $0.14 input / $0.28 output per million tokens, MIT licensed, 1M context, 284B/13B-active MoE architecture. Output cost is roughly 1/100 of GPT-5.5. For mid-volume work that wants frontier-class reasoning, Gemini 3 Flash at $0.50/$3 with 90.4% GPQA Diamond is the strongest choice.
When should I use multiple AI models instead of one?
Almost always, in production. Different task types reward different models, and routing across them costs nothing operationally with tools like OpenRouter (300+ models behind one OpenAI-compatible endpoint), Cursor's model picker, or Claude Code's /model switch. Set a primary, configure a fallback chain, route by cost ceiling and latency budget. The default-to-one-model habit is expensive.
How do I keep up with frontier model changes?
Re-verify before any decision over $100 a month. Five frontier models have shipped in the eleven days since the original outline for this article was written. The framework holds; the names change. Subscribe to each lab's release notes feed, and treat anything older than two weeks as a data point that may have moved.
